
在使用 Prometheus 进行监控的时候,通过 AlertManager 来进行告警,但是有很多人对报警的相关配置比较迷糊,不太清楚具体什么时候会进行告警。下面我们来简单介绍下 AlertManager 中的几个容易混淆的参数。
首先在 Prometheus 中有两个全局的参数 scrape_interval 和 evaluation_interval 。其中 scrape_interval 参数表示的是 Prometheus 从各种 metrics 接口抓取指标数据的时间间隔,evaluation_interval 参数表示的是 Prometheus 对报警规则进行评估计算的时间间隔。
当一条告警规则评估后,它的状态可能是 inactive、pending 或者 firing 中的一种。评估之后,状态将被发送到关联的 AlertManager 以进行潜在地开始或者停止告警通知的发送。
然后就是 AlertManager 中配置的 group_by 参数起作用的地方了,为了避免连续发送类似的告警通知,可以将相关告警分到同一组中进行告警。分组机制可以将详细的告警信息合并成一个通知,在某些情况下,比如由于系统宕机导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知,避免一次性接受大量的告警通知:
group_by: ['alertname', 'job']当一个新的报警分组被创建后,需要等待至少 group_wait 时间来初始化告警。
这样实际上就缓冲了从 Prometheus 发送到 AlertManager 的告警,将告警按相同的标签分组,而不必全都发送:
group_by: ['alertname', 'job']
group_wait: 45s # 通常设置成0s ~ 几分钟但是这可能也导致了接收到的告警通知的等待时间更长了。另外一个问题是下次对告警规则进行评估的时候,我们将再次收到相同的分组告警通知,这个时候我们可以使用 group_interval 参数来进行配置,当上一个告警通知发送到一个 group 后,我们在等待 group_interval 时长后,然后再将触发的告警以及已解决的告警发送给 receiver:
group_by: ['instance', 'job']
group_wait: 45s
group_interval: 10m # 通常设置成5分钟以上除此之外还有一个 repeat_interval 参数,该参数主要是用于配置告警信息已经发送成功后,再次被触发发送的时间间隔,一般不同类型的告警业务改参数配置不太一样,对于比较重要紧急的可以将改参数设置稍微小点,对于不太紧急的可以设置稍微大点。
上面这些都是在 Prometheus 或者 AlertManager 中配置的一些全局的参数,对于具体的告警规则还有时间可以配置,如下所示的告警规则:
groups:
- name: test-node-mem
rules:
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90
for: 1m
labels:
team: node
annotations:
summary: "{{$labels.instance}}: High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 90% (current value is: {{ $value }}"上面我们定义了一个名为 test-node-mem 的报警规则分组,一条报警规则主要由以下几部分组成:
-
alert:告警规则的名称 -
expr:是用于进行报警规则 PromQL 查询语句 -
for:评估等待时间(Pending Duration),用于表示只有当触发条件持续一段时间后才发送告警,在等待期间新产生的告警状态为pending -
labels:自定义标签,允许用户指定额外的标签列表,把它们附加在告警上 -
annotations:指定了另一组标签,它们不被当做告警实例的身份标识,它们经常用于存储一些额外的信息,用于报警信息的展示之类的
其中的 for 字段同样会影响到我们的告警到达时间,该参数用于表示只有当触发条件持续一段时间后才发送告警,在等待期间新产生的告警状态为pending,这个参数主要用于降噪,很多类似响应时间这样的指标都是有抖动的,通过指定 Pending Duration,我们可以过滤掉这些瞬时抖动,可以让我们能够把注意力放在真正有持续影响的问题上。
所以有的情况下计算我们的监控图表上面已经有部分指标达到了告警的阈值了,但是并不一定会触发告警规则,比如我们上面的规则中,设置的是1分钟的 Pending Duration,对于下图这种情况就不会触发告警,因为持续时间太短,没有达到一分钟:
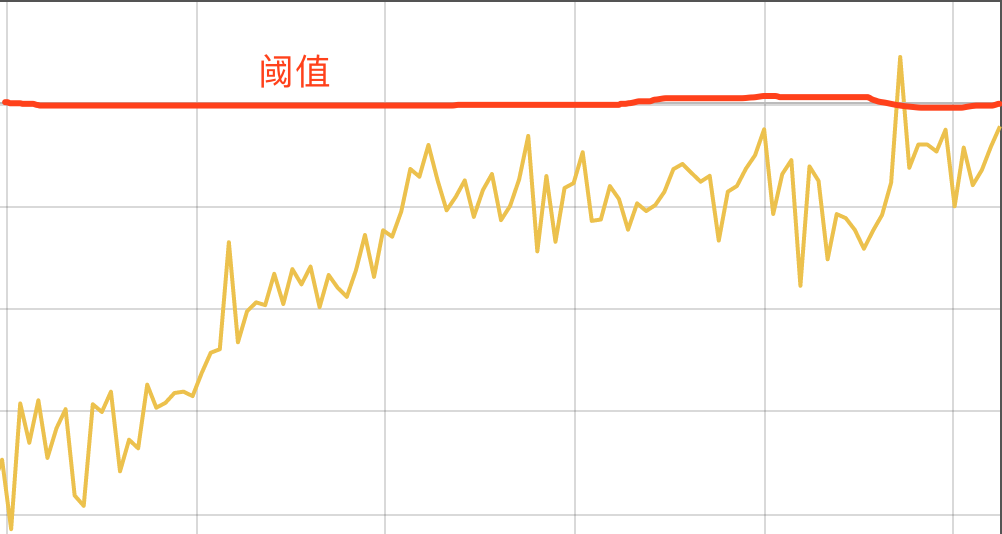
如果告警规则超过阈值的持续时间超过了 Pending Duration 那么就会触发告警了,告警产生后,还要经过 Alertmanager 的分组、抑制处理、静默处理、去重处理和降噪处理最后再发送给接收者。所以从一条告警规则被评估到触发告警再到发送给接收方,中间会有一系列的各种因素进行干预,所以有时候在监控图表上看到已经达到了阈值而最终没有收到监控报警也就不足为奇了。

扫描下面的二维码关注我们的微信公众帐号,在微信公众帐号中回复◉加群◉即可加入到我们的 kubernetes 讨论群里面共同学习。





