
容器化和微服务,让世界花枝招展,又支离破碎。一个典型的运行在容器云之上的微服务架构的应用,通常是由多种服务和基础设施的支撑而来的。这对运维工作提出一个很大的挑战 —— 一个应用后端的众多系统,究竟是怎样的工作状况?
事实上,所有构成这一应用的微服务以及支撑这一应用的所有基础设施,都会有各自的日志、指标数据,以及构建在上游的监控、日志系统。各处分散的数据和系统,会给支持团队造成极大的负担,也最终成为开发运维工作的拦路虎。
之前的经验中,可以把自家应用的各种业务、技术指标通过 Zabbix 或者 influxDB 进行存储,经由 Grafana 的插件系统进行整合展示,目前流行的容器云支撑系统 Kubernetes,也能够通过 influxDB 在 Grafana 上展示 Heapster 搜集到的数据。指标的事情解决了,下面自然就是日志了。
Grafana 也提供了针对 Elasticsearch 的数据源插件。下面用 Kubernetes 中正在运行的日志收集实例来展示 Grafana 对 ES 的支持。
建立数据源
首先是建立一个 Elasticsearch 类型的数据源。这里使用了一个 Kubernetes 集群的 ES 日志。Type 部分选择 Elasticsearch,然后填写 URL 地址、认证方式。Index name 填写 logstash-*。大致如图所示。
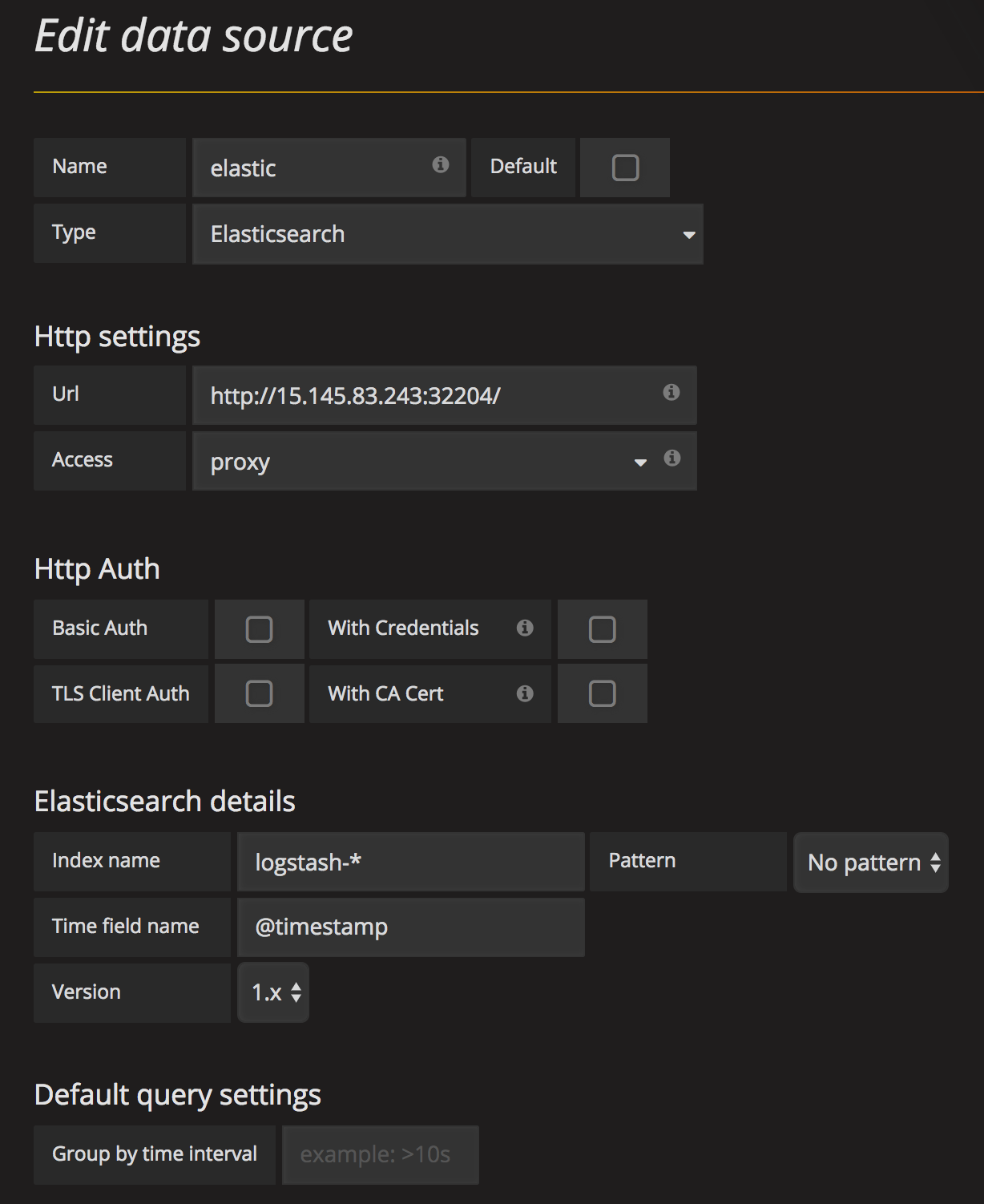
点击下面的 Test & Save,测试成功后完成数据源设置。
Access 一般来说都是选择 Proxy,也就是服务器间通信。
建立指标
接下来进入展示环节。利用新建的 ES 数据源,来建立展示单元。
曲线图
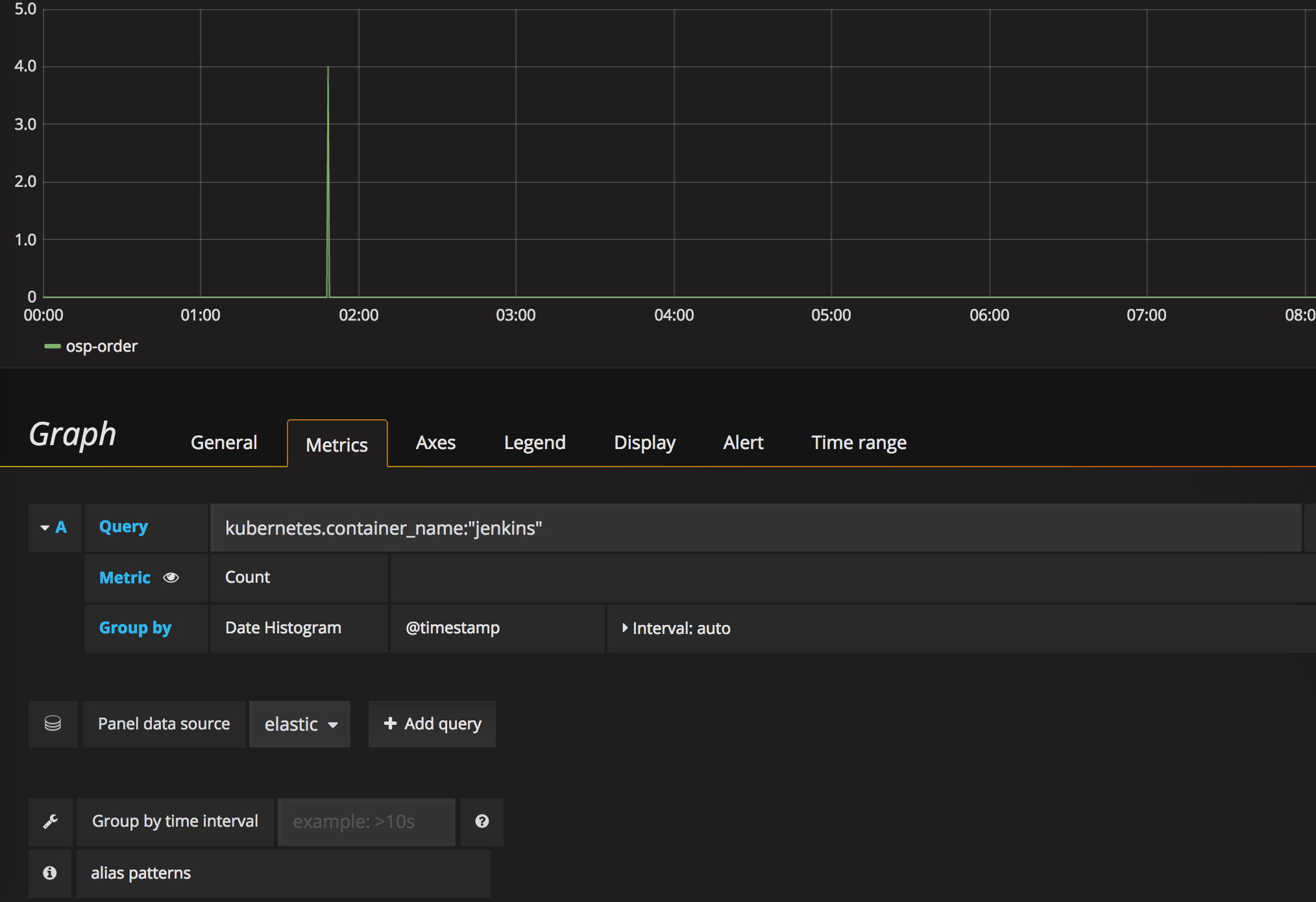
首先建立一个 Graph Panel,数据源选择上面新建的 ES。
Query 一栏需要按照 Lucene 语法进行查询。这里我们选择 kubernetes.container_name: "jenkins",也就是容器名称为 “jenkins” 的日志项。
其他可以保持缺省即可。
配置结束之后,稍等几秒钟,就会出现数据点。
日志表格
个人感觉上面的的数字在日志来说用处并不大,我们的目的还是在同一界面下查看日志。
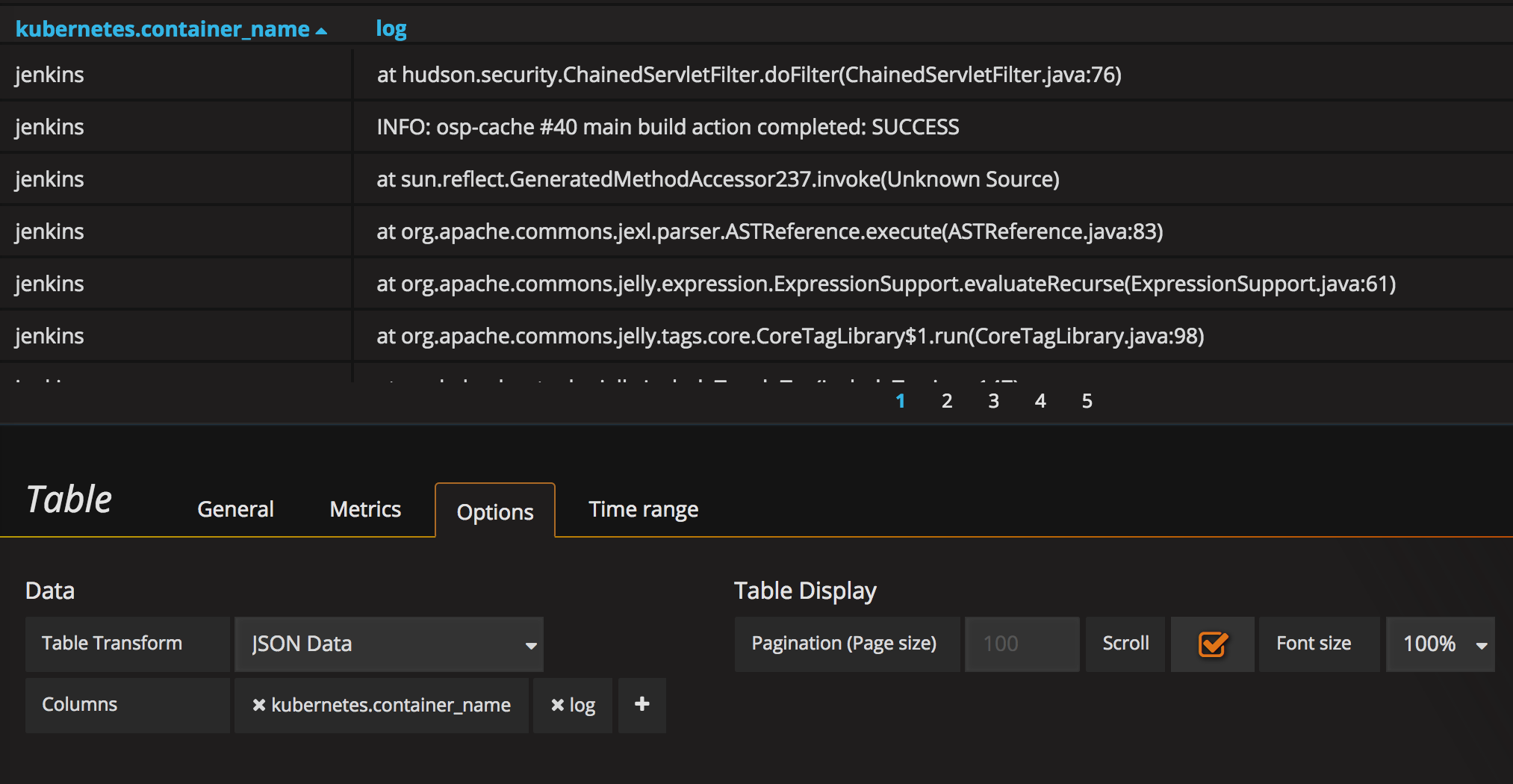
建立一个 Table Panel。配置数据源为 ES。Metric 选择 Raw Document。
经过短暂等候,上面表格会出现一堆的 JSON 文本,我们要通过 Options 来进行展现配置。
在 Columns 中我们简单的新加两列:”kubernetes.container_name” 和 “log”,就会以表格的形式把这两列展示出来。
告一段落
至此,Grafana 就成为一个集成了众多来源的运维入口。经过进一步的加工和配置(其实非常大量非常琐碎),仅从这一个入口就能够完成很多的日常巡检任务;更重要的是,因为数据的统一展示,在业务、服务和基础设施之间建立了直观的联系,为事故的处理甚至预测,提供了更多的便利条件。
文章来源于互联网:Grafana 和 Elasticsearch




