
领导说,只要机器够多,故障是个很平常的事情。
Kubernetes 能很好的管理容器和节点,所以正常的节点故障或者个别应用的故障是不会影响集群运作的。一旦 apiserver 或者所依赖的 etcd 出现问题,情况就不再乐观了。幸好这两个核心服务都提供了高可用相关能力。同时 controller-manager 以及 scheduler 也都具备通过选举产生 leadership 的机制,这就提供了高可用的基础。下面讲讲 Master 组件的高可用部署方式。
部署目标
-
每个 apiserver 都使用不同的负载均衡端点访问整个 etcd 集群。
-
每个 controller-manager 和 scheduler 使用各自的 apiserver 进行工作。
-
客户端通过负载均衡机访问 apiserver。
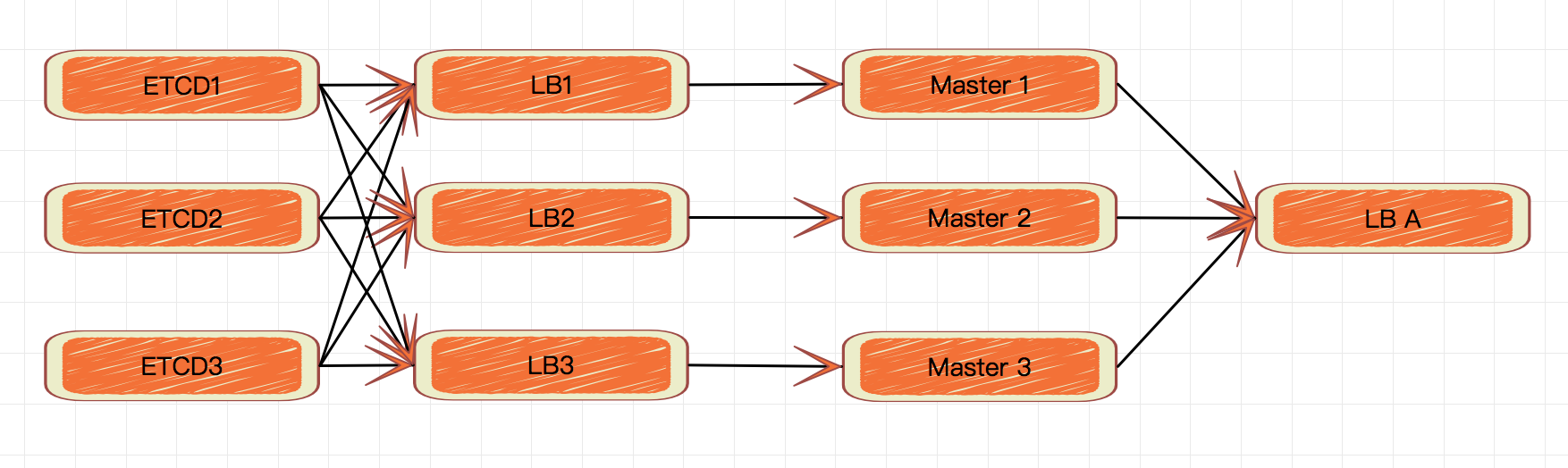
前提条件
这里我们假设,ETCD 集群已经成功建立,包含三个节点,采用 https 访问进行访问;Master 节点只有一个。也同样的使用 https 进行访问,集群能够正常工作。
另外准备若干台服务器安装 haproxy 充当负载均衡。
ETCD
众所周知的是,apiserver 的 --etcd-servers 参数是可以输入一整个 etcd 集群的,然而在使用中我们发现,一些特定版本的 apiserver 在 第一台 etcd 服务所在节点的特殊故障情况下,虽然 etcd 本身已经能够发现集群健康状态异常,却依然会陷入假死状态,,具体症状是多数 kubectl 的 Workload 相关操作都能完成,然而却不会真正生效。因此我们需要更可靠的对 etcd 集群的访问方式,降低 apiserver 缺陷造成的集群不可用的风险。
因为采用了 https 方式进行访问,所以这里我们 haproxy 的配置需要使用 tcp 方式。
不用 https 端点(也就是对外 https 对内 http 的部署)的方式,纯属个人习惯。
在启用 haproxy 之前,注意要把服务端证书的 IP 进行扩展,令其支持新增的负载均衡地址。
简单粗暴上代码:
...
frontend in-etcd
bind *:12379
mode tcp
default_backend etcd-cluster
backend etcd-cluster
mode tcp
balance roundrobin
option httpchk GET /health
http-check expect string true
server app1 10.211.55.9:2379 check check-ssl verify none
server app2 10.211.55.10:2379 check check-ssl verify none
server app3 10.211.55.11:2379 check check-ssl verify none
...
-
使用负载均衡节点的 12379 端口对外提供服务。
-
前后端均使用 tcp 方式。
-
利用 etcd 节点的
/health端点进行健康检查,健康标准是返回字符串true。 -
不校验 etcd 服务端证书。
启用 haproxy 之后,访问 haproxy 的状态页面,可以看到 etcd 集群的代理已经建立。
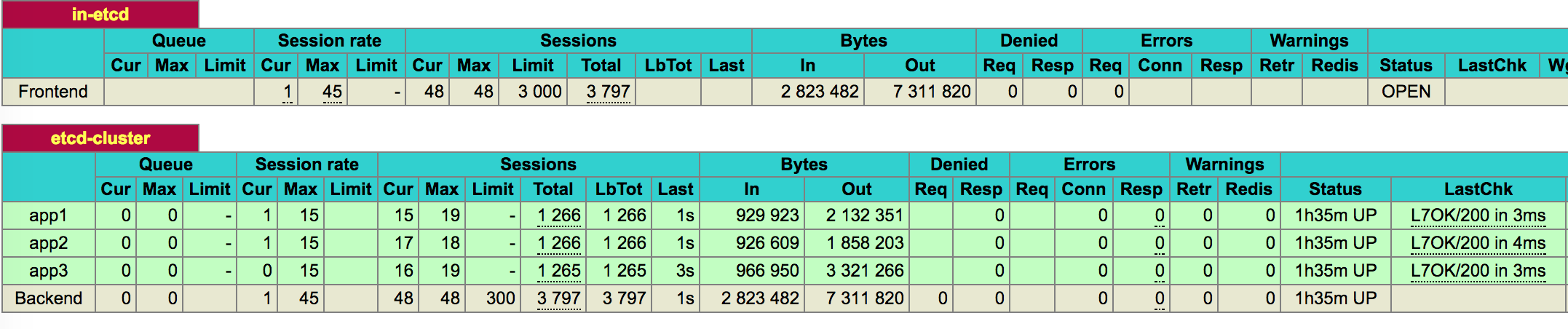
任意停止其中一台,会看到在检测窗口过后,对应的服务器状态切换为 DOWN。
用同样的方式部署其他两台 haproxy 服务器。
Master 组件
和 etcd 情况一样,apiserver 的服务证书,也需要更新,加入新的 Master 节点以及前端负载均衡的地址。
首先更改 apiserver 的 etcd 参数,从原来的三台 etcd 变更为单一的 haproxy 地址,例如 https://haproxy1:12379。修改之后,重新启动服务,可以看到服务正常启动成功。
接下来,我们将 apiserver、controller-manager 以及 scheduler 的可执行文件、服务定义、相关证书以及配置文件复制到新加入的服务器中,并启用服务。
-
每个 apiserver 需要配置各自的 etcd haproxy。
-
每个 scheduler 和 controller-manager 都访问各自的 apiserver 服务,并使用参数
--leader-elect启用选举(这一参数是缺省启用的)。
和 etcd 类似,为 apiserver 配置 haproxy:
frontend in-apiserver
bind *:16443
mode tcp
default_backend apiserver-cluster
backend apiserver-cluster
mode tcp
balance roundrobin
option httpchk GET /healthz
http-check expect string ok
server app1 10.211.55.9:6443 check check-ssl verify none
server app2 10.211.55.10:6443 check check-ssl verify none
server app3 10.211.55.11:6443 check check-ssl verify none
这里我们访问 apiserver 的 /healthz 端点,如果得到返回内容为 ok,则判断集群为健康。
配置后启动 haproxy,查看状态页面,可以看到 apiserver 集群也已经就绪。
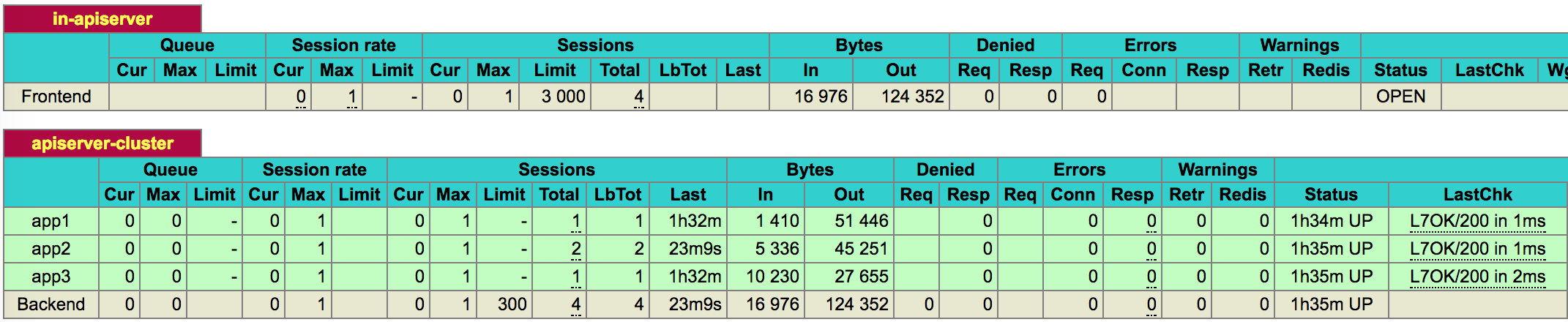
最后可以修改 kubectl 以及各个 Node 的 kubelet/kube-proxy apiserver 参数到负载均衡地址。
测试
停止任意一台 Master 的服务,包括 apiserver/controller-manager/scheduler,会看到 controller-manager 或 scheduler 的选举过程。如果停掉的是 apiserver,则可以在 haproxy 状态页上看到集群可用性的变化。
文章来源于互联网:搭建高可用 Kubernetes 集群




