
地址
Kubenurse:https://github.com/postfinance/kubenurse
简介
在 Kubernetes 集群运行中,一个常见故障就是集群内网络故障,经常会因为临时策略变更或者网络抖动导致一些古怪问题,而实际场景里的虚拟机和网络的监控经常是由其它部门管理的,如果从业务和 Kubernetes 这样的上层设施着手,可能需要一些时间才能解决问题。kubenurse 项目使用 HTTP 检测的方式提供了常用的几个监控指标。
这个工具的实现也很直接,用 Daemonset 的形式部署在每个集群节点上,每个 Pod 都会通过 HTTP 检测的方式对上述几种目标分别进行访问,最后用 Prometheus Summary 指标的形式暴露出来用于监控。检测机制如图所示:
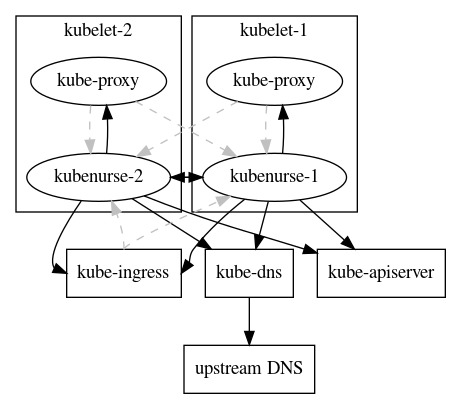
每个 Pod 都开放了 8080 的 http 端口,包含以下端点:
-
/或者/alive:返回本节点信息 -
/alwayshappy:返回 HTTP 200 用于心跳 -
/metrics:暴露 Prometheus 指标数据
/alive 返回的节点信息如下:
{
"api_server_direct": "ok",
"api_server_dns": "ok",
"me_ingress": "ok",
"me_service": "ok",
"hostname": "kubenurse-1234-x2bwx",
"neighbourhood_state": "ok",
"neighbourhood": [
{
"PodName": "kubenurse-1234-8fh2x",
"PodIP": "10.10.10.67",
"HostIP": "10.12.12.66",
"NodeName": "k8s-66.example.com",
"Phase": "Running"
},
{
"PodName": "kubenurse-1234-ffjbs",
"PodIP": "10.10.10.138",
"HostIP": "10.12.12.89",
"NodeName": "k8s-89.example.com",
"Phase": "Running"
}
],
"headers": {
"Accept": [
"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8"
],
"Accept-Encoding": [
"gzip, deflate, br"
],
...
}
}
可以看到,其中包含了上述所说的几个检测结果。
部署
源码中包含了一个 example 目录,简单地 kubectl apply 就可以完成部署,这里有两个可能需要修改的地方:
- 缺省命名空间是
kube-system,建议查找替换,并要注意调整 RBAC 授权。 - 涉及 Ingress 检测,因此要注意提供正确的域名。
监控
部署成功之后,Prometheus 会根据 Daemonset 中的注解采集数据:
...
annotations:
prometheus.io/path: "/metrics"
prometheus.io/port: "8080"
prometheus.io/scheme: "http"
prometheus.io/scrape: "true"
...
访问任意 Pod 的 :8080/metrics 端点,会看到如下指标:
-
kubenurse_errors:如果检测过程中出现错误,这个计数器会进行累加。 -
kubenurse_request:一个 Summary 类型的指标,正常检测结果的时间消耗分布。
这两个指标使用 type 标签对结果进行标识,对应几种不同的检测目标:
-
api_server_direct:从节点直接检测 API Server -
api_server_dns:从节点通过 DNS 检测 API Server -
me_ingress:通过 Ingress 检测本服务 Service -
me_service:使用 Service 检测本服务 Service -
path_$KUBELET_HOSTNAME:节点之间的互相检测
如此一来,我们就可以根据各种延迟时间的分布情况,以及返回错误的数量来确认集群网络状况了。
注意
节点较多时,每次采集可能会产生 n*(n-1) 次访问,会造成较重负载,可以给 Pod 打标签,并使用标签过滤的方式来减少请求,但是这样一来,就会导致检测结果不够全面的问题,因此还需对实际应用进行权衡。
文章来源于互联网:介绍一个小工具:KubeNurse——集群网络监控




