
最近加入 CNCF 成为沙箱项目的 Karmada 项目是一个开放的多 Kubernetes 管理工具,从 Kubernetes Federation 1⁄2 继承的大量经验,让这个项目有成为多集群管理首选产品的潜力。Karmada 具有开箱即用的跨集群调度能力,简单的使用 PropagationPolicy 就能将 Deployment、Service 这样的原生 Kubernetes 对象在多个集群之间进行灵活的调度。
工作负载的分配结束之后,还有个重要的问题就是流量分配了——多集群管理加上流量分配,会有很多有意思的事情可以完成,例如蓝绿灰度金丝雀,集群维护升级等等。实际包括各种网格、API 网关方案在内的很多产品,都有提供跨集群流量管理方案可用。这个例子里我选择了 Pipy 来搭档完成任务,Flomesh 出品的这个东西可塑性很强,除了轻量、快速之外,更重要的是能够用高级语言对流量进行编程,最新版本还为插件模型加入了图形交互界面。
整个原型大致架构如下:
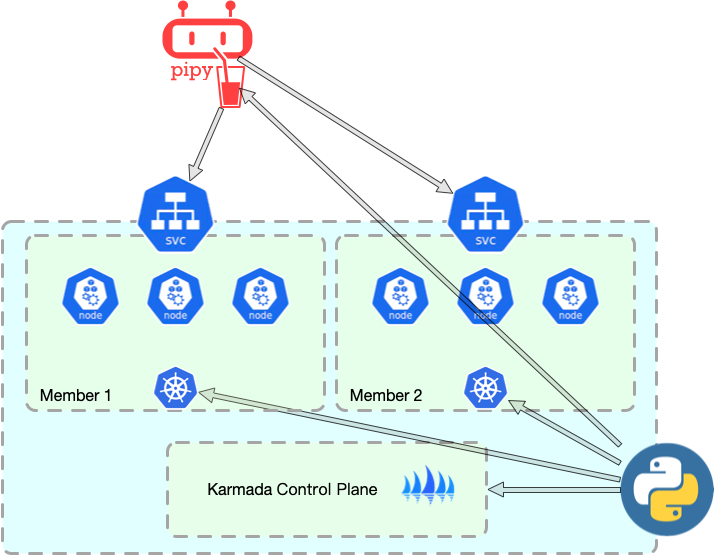
- 创建 Karmada 管理集群,并部署 Karmada。
- 纳管两个集群,分别命名为
member1和member2 - 部署 Deployment,并分布到两个集群
- 部署 Service,用 NodePort 方式开放服务,分发到集群
- 将暴露的服务端口同步给 Pipy,完成流量分发
部署 Karmada 集群
Karmada 的远程部署需要有一个运行的 Kubernetes 集群,然后克隆代码库,运行其中的 hack/remote-up-karmada.sh 脚本即可,命令行 ./remote-up-karmada.sh ~/.kube/config admin@v19 表示在 ~/.kube/config 配置文件中 admin@v19 上下文所指代的集群中部署 Karmada 控制平面。
部署之前,有两个需要注意的点:
- 如果要在
arm64平台上运行,可以将脚本中的镜像改为dustise/****:v0.0009-29-gc2030ca6 -
如果像我一样偏偏使用 NodePort 方式暴露 Karmada API Server,在
deploy-karmada.sh的 203 行installCRDs语句之前加入一个read -p "Review your kubeconfig, then press [Enter] key to continue..",脚本运行至此会暂停工作,修改 kubeconfig 文件中新出现的karmada-apiserver上下文中的服务器即可,例如:- cluster: insecure-skip-tls-verify: true server: https://10.211.55.58:32016 name: karmada-apiserver
安装器会在集群中生成 kamada-system 命名空间,在其中运行一个自己的 API Server,用于提供集群管理服务,并拉取认证信息到指定 Kubeconfig。
纳管集群
完成部署之后,可以在 Karmada 项目的 Release 页面上下载 karmada 用客户端 karmadactl 来加入集群了,例如:
$ kubectl karmada join member2
--cluster-kubeconfig=./total.yaml
--cluster-context=admin@karmada2
为了方便使用,上面的命令把 karmada 客户端设置成为了
krew插件,实际上直接解压使用二进制也是等效的。
和部署控制平面的命令类似,Karmada CLI 也是使用指定 kubeconfig 和上下文的方式,获取集群操作权限,把集群加入 Karmada。
Karmada 加入新集群之后,会在它的管理面 API Server 中注册一个 Cluster 对象,下面是加入了两个集群之后的样子:
$ kubectl get clusters
NAME VERSION MODE READY AGE
member1 v1.19.15 Push True 13h
member2 v1.19.15 Push True 13h
操作成员集群
既然是对象,就可以看看他葫芦里卖的是什么 YAML 了:
apiVersion: cluster.karmada.io/v1alpha1
kind: Cluster
metadata:
creationTimestamp: "2021-10-14T11:51:54Z"
finalizers:
- karmada.io/cluster-controller
generation: 1
name: member1
...
spec:
apiEndpoint: https://10.211.55.61:6443
secretRef:
name: member1
namespace: karmada-cluster
syncMode: Push
status:
apiEnablements:
- groupVersion: v1
resources:
- kind: Binding
name: bindings
- kind: ComponentStatus
name: componentstatuses
- kind: ConfigMap
name: configmaps
- kind: Endpoints
name: endpoints
...
conditions:
- lastTransitionTime: "2021-10-14T13:52:31Z"
message: cluster is reachable and health endpoint responded with ok
reason: ClusterReady
status: "True"
type: Ready
kubernetesVersion: v1.19.15
nodeSummary:
readyNum: 1
totalNum: 1
resourceSummary:
allocatable:
cpu: "2"
ephemeral-storage: "59200992363"
hugepages-1Gi: "0"
hugepages-2Mi: "0"
hugepages-32Mi: "0"
hugepages-64Ki: "0"
memory: 1927288Ki
pods: "110"
allocated:
cpu: "1"
ephemeral-storage: "0"
memory: 140Mi
pods: "10"
allocating:
cpu: "0"
ephemeral-storage: "0"
memory: "0"
pods: "0"
会发现这里对集群的描述很像节点,状态字段中包含了:
- 资源情况
- 可接受的对象类型
- 运行状况
而 spec字段中的内容则包含了集群的访问端点和一个对 Secret 对象的引用,查看一下其中的内容:
$ kubectl view-secret -n karmada-cluster member1
Multiple sub keys found. Specify another argument, one of:
-> caBundle
-> token
$ kubectl view-secret -n karmada-cluster member1 caBundle
-----BEGIN CERTIFICATE-----
MIIC5zCCAc+gAwIBAgIBADANBgkqhkiG9w0BAQsFADAVMRMwEQYDVQQDEwprdWJl
...
-----END CERTIFICATE-----
$ kubectl view-secret -n karmada-cluster member1 token
eyJhbGciOiJSUzI1NiIsImtpZCI6ImRqZTY2OGVua0ltSHA2UGJ3LUZHQ0V
...
看起来这是个访问 Kubernetes 使用的凭据,我们可以导出 caBundle 测试一下:
$ kubectl --certificate-authority=member1/caBundle.pem
--server=https://10.211.55.61:6443 --token=eyJhb...
get nodes
NAME STATUS ROLES AGE VERSION
karmada1 Ready master 37h v1.19.15
果然返回了集群信息。
Karmada v0.9.0 中的 Cluster 对象属于 cluster.karmada.io/v1alpha1,因此可以用如下代码获取集群信息:
crd = client.CustomObjectsApi(karmada_config)
member_list = crd.list_cluster_custom_object(group="cluster.karmada.io",
version="v1alpha1", plural="clusters")
而根据前面的尝试,用这个结果连接集群也是很方便的:
secret_name = member_obj["spec"]["secretRef"]["name"]
secret_ns = member_obj["spec"]["secretRef"]["namespace"]
secret_client = client.CoreV1Api(karmada_config)
secret_obj = secret_client.read_namespaced_secret(secret_name, secret_ns)
server_token = secret_obj.data["token"]
server = member_obj["spec"]["apiEndpoint"]
cfg = config.kube_config.Configuration()
cfg.host = server
cfg.api_key = {'authorization': 'Bearer ' + base64.b64decode(server_token.encode("ascii")).decode("ascii")}
cfg.verify_ssl = False
api_client = client.api_client.ApiClient(cfg)
部署应用
创建一个 Deployment:
$ kubectl create deploy flask --image=dustise/flaskapp:v0.2.7
...
deployment.apps/flask scaled
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
flask 0/4 0 0 13h
这里我们创建一个 Deployment,并设置为四副本运行,在控制面看来,这个 Deployment 无法运行,也没有生成 Replicaset,接下来我们为它设置一个传播策略:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: flask
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: flask
placement:
clusterAffinity:
clusterNames:
- member1
- member2
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- member1
weight: 1
- targetCluster:
clusterNames:
- member2
weight: 1
提交之后,可以看到成员集群按照我们设置的权重来创建 Pod:
$ k1 get po ; k2 get po
NAME READY STATUS RESTARTS AGE
flask-6d75654674-54c7p 1/1 Running 0 34s
flask-6d75654674-qgbjg 1/1 Running 0 34s
NAME READY STATUS RESTARTS AGE
flask-6d75654674-7d5vl 1/1 Running 0 3s
flask-6d75654674-9ns6n 1/1 Running 0 112s
~~~
缩容到 2 实例:
k1 get po ; k2 get po
NAME READY STATUS RESTARTS AGE
flask-6d75654674-54c7p 0/1 Terminating 0 2m14s
flask-6d75654674-qgbjg 1/1 Running 0 2m14s
NAME READY STATUS RESTARTS AGE
flask-6d75654674-9ns6n 1/1 Running 0 3m32s
Pod 运行起来之后,我们来部署一个 Service:
apiVersion: v1
kind: Service
metadata:
labels:
app: flask
name: flask
spec:
ports:
- name: http
port: 80
selector:
app: flask
type: NodePort
创建之后,会发现 Karmada 为新服务分配了端口,Endpoint 是没有的:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
flask NodePort 10.110.144.229 80:31193/TCP 13h
kubernetes ClusterIP 10.96.0.1 443/TCP 41h
$ kubectl get ep
NAME ENDPOINTS AGE
kubernetes 10.211.55.58:5443 41h
同样创建一个 pp,把 Service 分配给集群。完成分发后就可以访问各个集群的服务了。
有时候有人跟你说 PP 其实不是耍流氓,是在讨论 Karmada。
用 Pipy 做负载均衡
Pipy 的部署很方便,在 Release 页面下载二进制即可。源码中的 tutorial/08-load-balancing-improved 就是一个负载均衡的例子,这里我们对其配置做个简化:
这个例子中的 router 对象和 Kong Gateway 的概念类似,我们修改一下 config/router.json,仅包含一个对 /env/* 路径的转发:
{
"routes": {
"/env/*": "flask"
}
}
而 config/balancer.js 中则包含了对负载均衡池的定义,原文内容:
{
"services": {
"service-hi" : ["127.0.0.1:8080", "127.0.0.1:8082"],
"service-echo" : ["127.0.0.1:8081"],
"service-tell-ip" : ["127.0.0.1:8082"]
}
}
清理一下,只留下:
{
"services": {
"flask" : []
}
}
启动 Pipy:pipy --admin-port=8889 proxy.js,在 8889 启用了控制台端口,浏览器打开会看到类似界面:
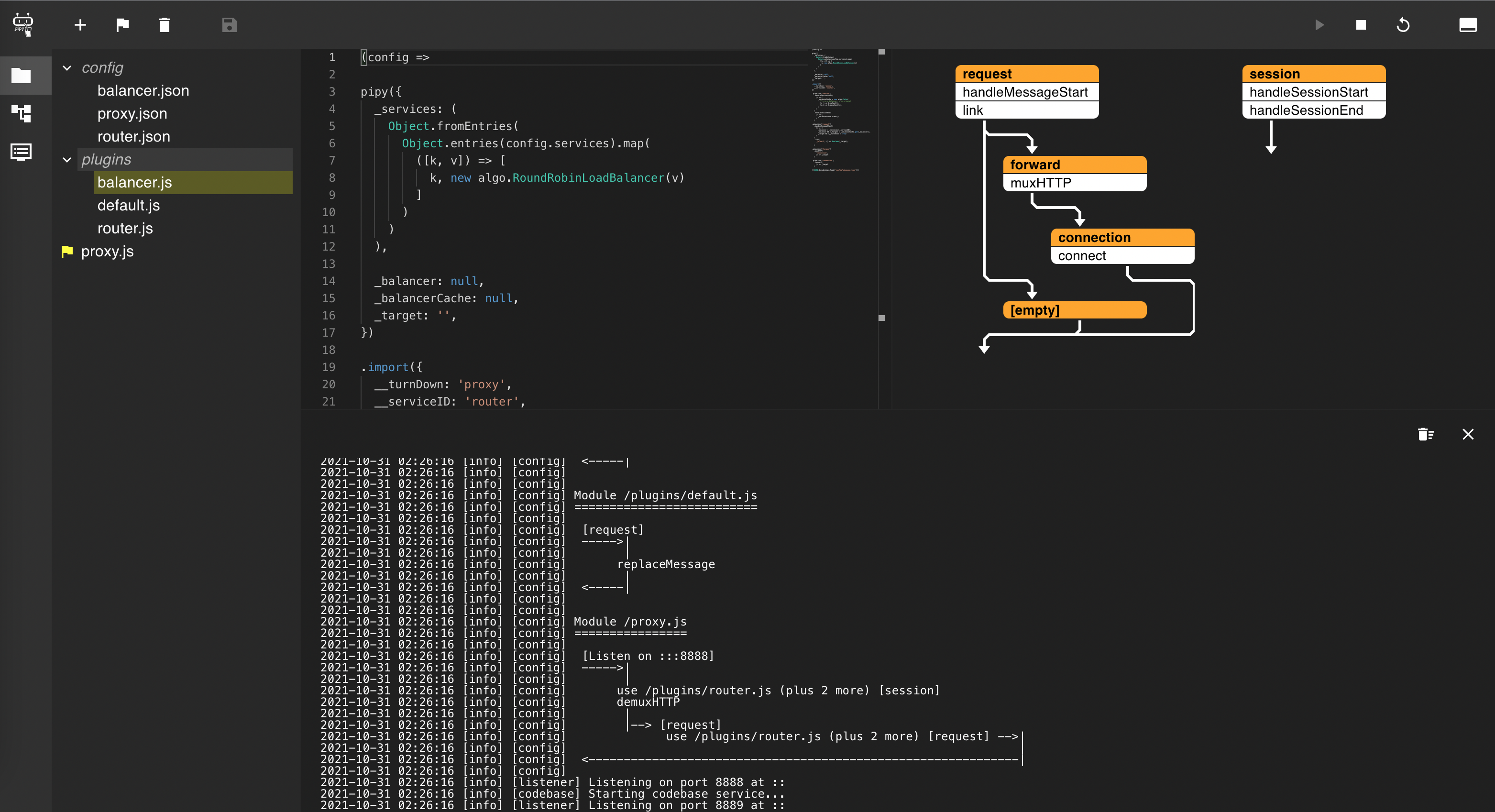
现在就可以在 config/proxy.json 中定义的代理端口中上访问我们部署在 Kubernetes 中的服务了。整个流程都非常清楚,这个服务发生任何变化,把新的开放端口写入配置,刷新 Pipy 即可,大致代码如下:
# 列出 Karmada 集群
for cluster in members["items"]:
member_name = cluster["metadata"]["name"]
logging.info("Services in cluster {}".format(member_name))
cluster_client = karmada.get_member_client(cluster)
# 查找服务
services = karmada.list_service(cluster_client, "default", {"app": "flask"})
# 每个集群的节点
nodes = karmada.list_nodes(cluster_client)
address_list = []
port_list = []
for node in nodes.items:
addresses = node.status.addresses
for address in addresses:
if address.type == "InternalIP":
logging.info("Found a node in {} with IP {}".format(member_name, address.address))
address_list.append(address.address)
break
for service in services.items:
port_list.append(service.spec.ports[0].node_port)
logging.info("Found service named {} in cluster {}".format(service.metadata.name, member_name))
# 组装 URL
for address in address_list:
for port in port_list:
lb_config["services"]["flask"].append("{}:{}".format(address, port))
最终结果写入 Pipy 配置,管理页面重载配置就完成了刷新。此时访问 Pipy 在 proxy.js 中定义的端口,就能看到负载均衡的效果了。
其实没这么简单
首先,我知道该用 watch :);
其次,在管理界面刷新配置是个挺傻的事情,Pipy 提供了 Repo 功能,可以进行热加载。这个组件也是 Pipy 高可用和控制平面、GitOps 的命门所在。
另外,在节点比较多的集群中,往往不会把所有节点用于暴露 NodePort,这时可以考虑使用节点标签来限制负载均衡池的生成情况。
最后直接生成 balancer.js 是个非常粗糙的行为,这种做法里,Pipy 必须独占,否则一次刷新可能就覆盖了其它服务的定义,因此这里最好能够使用 Annotation 或者 CRD 等方式,给集群、服务、节点做出标识,从而精确完成刷新过程。
相关链接
-
Karmada:
https://github.com/karmada-io/karmada -
Pipy:
https://github.com/flomesh-io/pipy
文章来源于互联网:用 Karmada 和 Pipy 搭建野生多集群




