
原文:Use Prometheus Vector Matching to get Kubernetes Utilization across any Pod Label
注:这里实际上涉及到两种标签,一个是 Pod 的,一个是 Metrics 的,非常容易混淆,所以会分别写成 Pod 标签和指标标签。
Prometheus 是为 Kubernetes 这样的动态环境而生的。它的服务发现能力和查询语言非常强大,Kubernetes 运维过程中,用户可以借 Prometheus 解决监控问题。
相对其它竞品来说,这种弹性直接提高了 Prometheus 的使用门槛,向量匹配 就是众多拦路虎中的一个。
Prometheus 文档中在这个主题上做了非常精彩的阐述,所以本文中不会做过多的细节阐述,而是会围绕资源使用率这个主题进行一些场景化的尝试。
用标签聚合内存用量
Kubernetes 提供了一个 container_memory_usage_bytes 指标,用于表达 Pod 的内存用量:
...
container_memory_usage_bytes{beta_kubernetes_io_arch="amd64",beta_kubernetes_io_fluentd_ds_ready="true",beta_kubernetes_io_instance_type="g1-small",beta_kubernetes_io_os="linux",cloud_google_com_gke_nodepool="small-preemptible",cloud_google_com_gke_preemptible="true",container_name="POD",failure_domain_beta_kubernetes_io_region="us-east1",failure_domain_beta_kubernetes_io_zone="us-east1-c",id="/kubepods/burstable/pod13d4221c-c484-11e7-bff5-42010af0018b/67e5bb069ab9881ff8a55b8628ef4935b0d1ace09c18df20db059522bdfd5b7d",image="gcr.io/google_containers/pause-amd64:3.0",instance="gke-latency-at-small-preemptible-0c981b61-9489",job="kubernetes-cadvisor",kubernetes_io_hostname="gke-latency-at-small-preemptible-0c981b61-9489",name="k8s_POD_latency-api-971504058-jzs5h_default_13d4221c-c484-11e7-bff5-42010af0018b_0",namespace="default",pod_name="latency-api-971504058-jzs5h"} 389120
container_memory_usage_bytes{beta_kubernetes_io_arch="amd64",beta_kubernetes_io_fluentd_ds_ready="true",beta_kubernetes_io_instance_type="g1-small",beta_kubernetes_io_os="linux",cloud_google_com_gke_nodepool="small-preemptible",cloud_google_com_gke_preemptible="true",container_name="POD",failure_domain_beta_kubernetes_io_region="us-east1",failure_domain_beta_kubernetes_io_zone="us-east1-c",id="/kubepods/burstable/pod81d0f651-c500-11e7-bff5-42010af0018b/309e05b118e618122c70ccf88538d13ca41c3b5a770d5d67882426854391c23c",image="gcr.io/google_containers/pause-amd64:3.0",instance="gke-latency-at-small-preemptible-0c981b61-9489",job="kubernetes-cadvisor",kubernetes_io_hostname="gke-latency-at-small-preemptible-0c981b61-9489",name="k8s_POD_latency-api-971504058-gszpw_default_81d0f651-c500-11e7-bff5-42010af0018b_0",namespace="default",pod_name="latency-api-971504058-gszpw"} 372736
container_memory_usage_bytes{beta_kubernetes_io_arch="amd64",beta_kubernetes_io_fluentd_ds_ready="true",beta_kubernetes_io_instance_type="g1-small",beta_kubernetes_io_os="linux",cloud_google_com_gke_nodepool="small-preemptible",cloud_google_com_gke_preemptible="true",container_name="latency-api",failure_domain_beta_kubernetes_io_region="us-east1",failure_domain_beta_kubernetes_io_zone="us-east1-c",id="/kubepods/burstable/pod13d4221c-c484-11e7-bff5-42010af0018b/497e6fdf2217771cb3f52e6fef93734d023f0e7f23f92c58d22139fc18dc5f13",image="registry.gitlab.com/latency.at/latencyat@sha256:8ea057e064b64cc9c8459a68ef3f6d0fc26169b4f57aef193831779e1fe713d4",instance="gke-latency-at-small-preemptible-0c981b61-9489",job="kubernetes-cadvisor",kubernetes_io_hostname="gke-latency-at-small-preemptible-0c981b61-9489",name="k8s_latency-api_latency-api-971504058-jzs5h_default_13d4221c-c484-11e7-bff5-42010af0018b_1",namespace="default",pod_name="latency-api-971504058-jzs5h"} 11014144
container_memory_usage_bytes{beta_kubernetes_io_arch="amd64",beta_kubernetes_io_fluentd_ds_ready="true",beta_kubernetes_io_instance_type="g1-small",beta_kubernetes_io_os="linux",cloud_google_com_gke_nodepool="small-preemptible",cloud_google_com_gke_preemptible="true",container_name="latency-api",failure_domain_beta_kubernetes_io_region="us-east1",failure_domain_beta_kubernetes_io_zone="us-east1-c",id="/kubepods/burstable/pod81d0f651-c500-11e7-bff5-42010af0018b/7b438a8e9df0cf1ab29d067fd36c97099f9f5e7e9257f6187c5be6bff846a62c",image="registry.gitlab.com/latency.at/latencyat@sha256:8ea057e064b64cc9c8459a68ef3f6d0fc26169b4f57aef193831779e1fe713d4",instance="gke-latency-at-small-preemptible-0c981b61-9489",job="kubernetes-cadvisor",kubernetes_io_hostname="gke-latency-at-small-preemptible-0c981b61-9489",name="k8s_latency-api_latency-api-971504058-gszpw_default_81d0f651-c500-11e7-bff5-42010af0018b_0",namespace="default",pod_name="latency-api-971504058-gszpw"} 11448320
...
但是很不幸,这其中并不包含 Pod 标签。还好,kube-state-metrics 提供了一个 kube_pod_labels 指标,这个指标包含一个静态时序,其中表达了 Pod 标签和 Pod 名称的关系:
可以用 (pod_name="latency-api-971504058-jzs5h") 来查询 Pod 的标签:
kube_pod_labels{instance="10.116.0.12:8080",job="kubernetes-service-endpoints",k8s_app="kube-state-metrics",kubernetes_name="kube-state-metrics",kubernetes_namespace="kube-system",label_app="latency-api",label_pod_template_hash="971504058",namespace="default",pod="latency-api-971504058-jzs5h"} 1
kube_pod_labels{instance="10.116.1.26:8080",job="kubernetes-service-endpoints",k8s_app="kube-state-metrics",kubernetes_name="kube-state-metrics",kubernetes_namespace="kube-system",label_app="latency-api",label_pod_template_hash="971504058",namespace="default",pod="latency-api-971504058-jzs5h"} 1
因为有两个 kube-state-metrics 实例在运行,所以出现了两条结果。这两个指标可以用向量匹配的方式进行合并。他们的值是一致的,所以用 min/max 都可以。后面的内容会用 label_app 进行聚合,所以需要保留这个指标标签。另外 pod 标签也是需要保留的,用于进行连接。因为在 kube_pod_labels 中,Pod 的指标标签是 pod,而在 containers_memory_usage_bytes 中则变成了 pod_name。因此需要用一个 label_replace 进行重命名:
max by (pod_name,label_app) (
label_replace(kube_pod_labels{label_app!=""},"pod_name","$1","pod","(.*)")
)
返回内容大致如下:
{label_app="latency-api",pod_name="latency-api-971504058-n8k6d"} 1
{label_app="latency-api",pod_name="latency-api-971504058-jzs5h"} 1
接下来就可以用向量匹配的方式来把 container_memory_usage_bytes 和前面的表达式进行合并了。这里用到了 *,他把内存用量乘以 kube_pod_labels 里面的匹配值,然而这个值总是 1,所以其实没什么作用。
每个 Pod 会有多个容器,也就是说可能有多个 container_memory_usage_bytes,因此需要用到 group_left。因为要保留 label_app 这一指标标签,所以用它作为 group_left 的参数。
container_memory_usage_bytes * on (pod_name) group_left(label_app)
max by (pod_name,label_app) (
label_replace(kube_pod_labels{label_app!=""},"pod_name","$1","pod","(.*)")
)
用下面的表达式,可以聚合所有 Pod 的内存用量指标:
sum by (label_app,namespace) (
container_memory_usage_bytes * on (pod_name) group_left(label_app)
max by (pod_name,label_app) (
label_replace(kube_pod_labels{label_app!=""},"pod_name","$1","pod","(.*)")
)
)
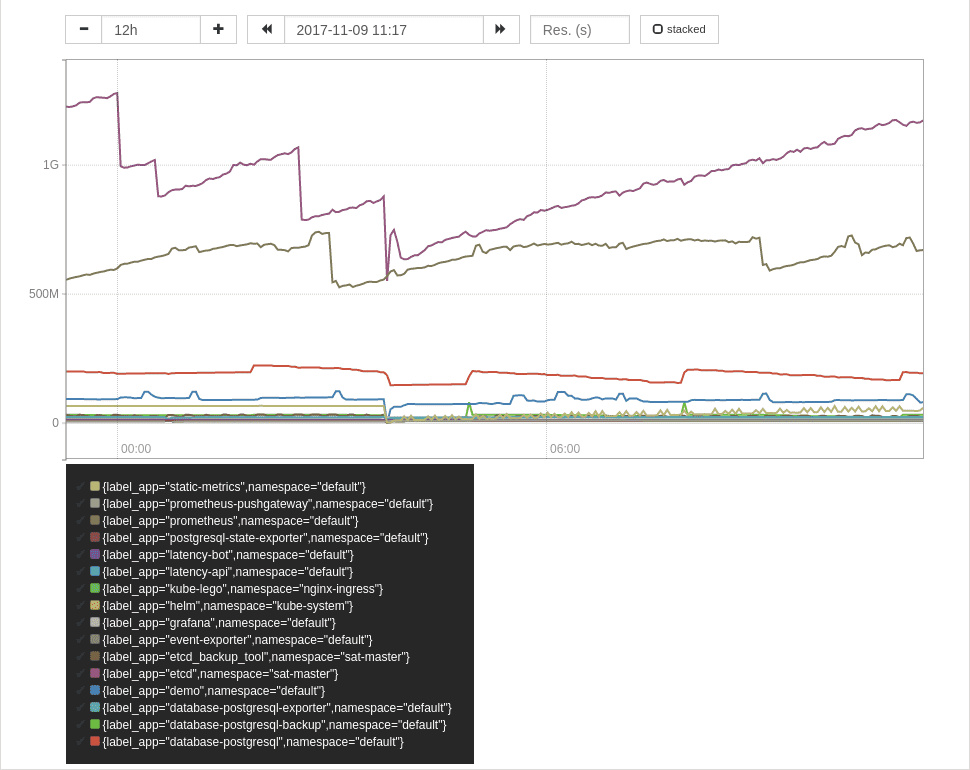
用 Pod 标签 对 CPU 和 IO 指标进行聚合
既然已经能把 kube_pod_labels 和 cadvisor 连接起来,那么这个能力范围就不仅限于内存了。
CPU
sum by (label_app,namespace) (
rate(container_cpu_usage_seconds_total[2m]) * on (pod_name) group_left(label_app)
max by (pod_name,label_app) (
label_replace(kube_pod_labels{label_app!=""},"pod_name","$1","pod","(.*)")
)
)
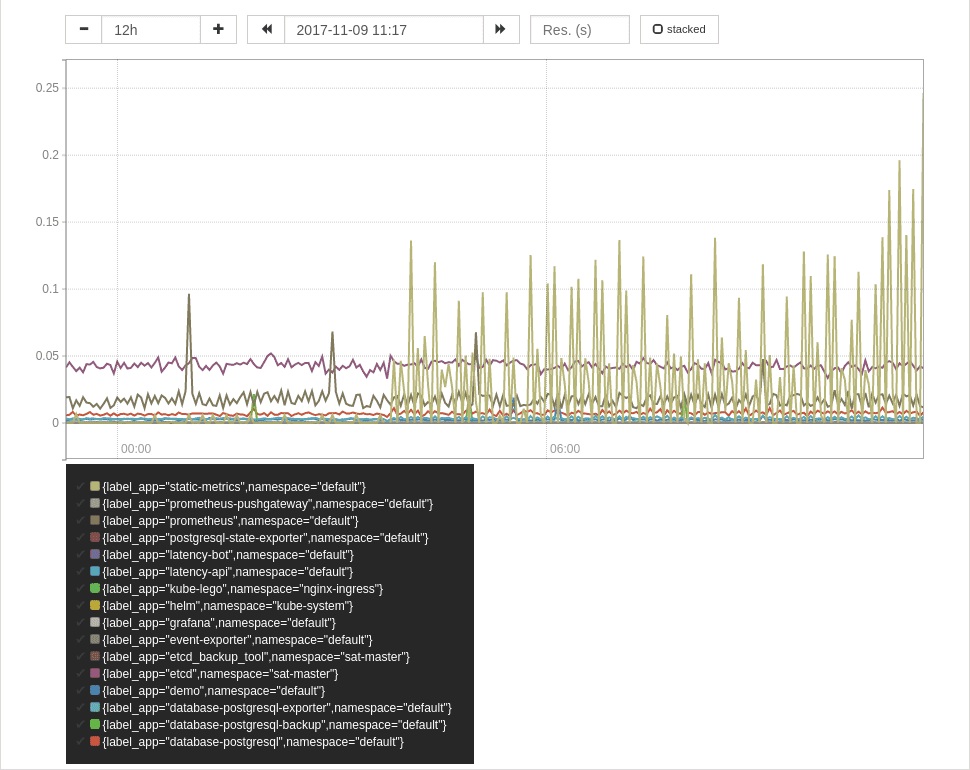
磁盘 IO
我曾经想要展示一些磁盘 IO 统计,很不幸,这个功能又出问题了。
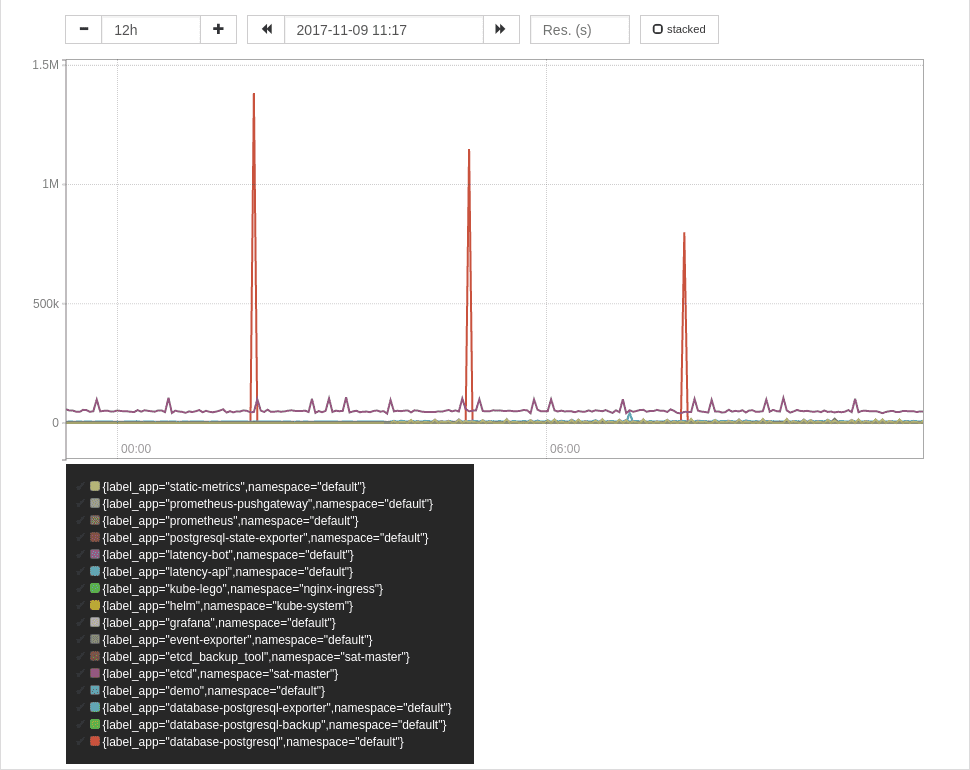
网络
sum by (label_app,namespace) (
rate(container_network_transmit_bytes_total[2m]) * on (pod_name) group_left(label_app)
max by (pod_name,label_app) (
label_replace(kube_pod_labels{label_app!=""},"pod_name","$1","pod","(.*)")
)
)
文章来源于互联网:Prometheus 和 Pod 标签




