
本文主要内容来自于 2023 年大连 Kubernete Community Day 的演讲《集群多还是多集群?——云原生平台工程探索》
第一页——听说 DevOps 死了
2022 年底,InfoQ 发了一篇爆款文,《DevOps 已死,平台工程才是未来》,这里总结了一个太长不看版:
- 开发者并不想做运维,工程师不仅编写代码,还要运行他们编写的代码;
- 反模式:高级工程师现在要负责环境配置,并需要处理比较初级的同事的请求;
- 除了 CICD 之外,还有很多复杂的运维场景:配置管理、依赖管理、跨环境部署、统一的安全管控..
- 虽然对于像谷歌、亚马逊、Airbnb 这些比较先进的组织来说,上述方法很有效,但对于其他大多数团队而言,要在实践中复制真正的 DevOps 并不简单。
还提到 Gartner 的炒作周期图,将平台工程定义为正在上升期的技术,并且会在 2-5 年达到平台期。
其实这部分回答了我一直以来的一个小迷惑——所谓大一统的运维平台/工具,到底有没有存在的意义?是不是说假设 DevOps 团队成长起来了,就不需要这种集中产出的工具和规范了?
首先,我们来看看 DevOps,DevOps 是一种文化,而非一种角色。在 DevOps 文化中,开发和运维团队需要更紧密地协作,共同为业务提供更好的服务。但这并不意味着所有开发人员都需要成为运维专家,或者所有运维人员都需要成为开发专家。
在实践中,即使是 DevOps 团队,也需要有明确的职责划分和专业分工。大一统的运维平台/工具的存在意义就在于它可以提供一种标准化和自动化的方式,使得 DevOps 团队能更高效地进行日常工作,而不需要过度关注具体的运维细节。这并不是说 DevOps 团队成长起来就不需要这种工具了,相反,随着团队的成熟,这种工具的价值会更加明显。
再来看看高级工程师组成的 DevOps 梦之队。虽然有一些高级工程师在多个技术领域都有深厚的造诣,但是他们的存在并不能解决所有问题。专家本身的技术一定是有所侧重和偏爱的,而且在多个不同种类的工作之间进行频繁切换会严重影响效率。而且,聘用多个领域的专家组成全职能 DevOps 团队的成本非常高,这对于大多数公司来说是不切实际的。
最后,我们来看看平台工程。平台工程将复杂的运维任务抽象为平台服务,由专门的平台工程团队提供支持。这样,开发团队就可以将更多的精力投入到业务开发上,而不是被运维问题所困扰。平台工程团队一般由具有深厚运维经验和开发能力的高级工程师组成,他们可以为开发团队提供高质量的平台服务,从而提高整个组织的开发效率。因此,平台工程才是未来的趋势。
关于平台工程的文章中一般还会提到一本书:《Team Topologies》,这本书中,详细描述了通常被称为成本中心的平台团队的服务范围、交付模式、运营内容等做了一番阐述,建议 SRE 工具建设领域的朋友们阅读本书增强自信。根据本书描述,有四种基本的拓扑结构,团队应该围绕这些拓扑结构进行:
- 业务导向团队:与业务领域某个部分的工作流相匹配,处理核心业务逻辑。
- 赋能团队:帮助业务导向团队克服障碍并检测缺失的功能。
- 复杂子系统团队:在严重依赖数学/技术方面的专业知识时组建。
- 平台团队:提供一个令人信服的内部平台,提高业务导向团队的交付速度。
各自为政有什么问题
下面说点常见的场景。
第三方软件选型和采用
首先说的是云原生,很多人都领略过 Cloudscope Landscape 的宏伟壮观。选型时无从下手,尤其是面对同类项目(例如 ELK 栈和 Loki 栈,Docker 和 Podman 等)时,社交网络定选型是个常态。
然而大家心里应该都清楚,引入一个“看上去不错”开源软件进入企业系统,是有很多需要考虑的内容的,例如:
- 项目健康度如何?例如社区活跃程度、Issue 响应速度、社区多样性等。
- 是否有商业公司提供支持?
- 软件本身是否满足其 License 要求?软件的 License 是否能够满足企业内使用的场景需求?
- 软件及其依赖项合法合规吗?
- 除了功能之外,稳定性、可靠性、安全性等非功能特性是否满足企业需要?
- 运维特性,例如倒换、扩缩容、升级、备份恢复等是否完善方案,用于支撑长期运行?
- …
软件选定之后还面临世界对接的问题,常见的问题包括认证、可观测性、存储等的对接,这些还是一些点状的功能,在云原生体系里,还有一个更严重的体系冲突问题。
我常用这张图来把“普通”开源软件和云原生软件的采用过程进行对比:
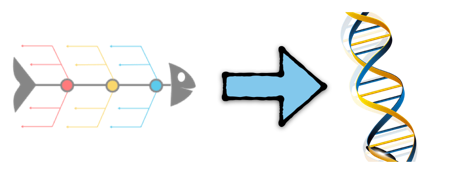
一个有一定规模的企业的 IT 体系,条条框框是相对固定的,软件规模不管大小,都可以服服帖帖、按部就班的落到代表体系规则的鱼骨图里,而以 Kubernetes 为代表的云原生生态则不同,其中自带了各种条条框框,不光是改了改你的部署运行方式,还对你的运维方式产生深远影响,甚至对你的应用架构指指点点。如果不照章办事,就可能和生态不兼容。因此云原生进入企业,通常会跟 IT 系统的现存规则交缠在一起,形成一种相互影响和制约的新体系。

用户又乱搞了
以我熟悉的 Kubernetes 为例,一些用户的操作,可能造成各种奇怪的不良后果,例如:
- 滥用节点反亲和导致无法调度
- 引入网络恶意镜像损失算力甚至被盗取机密
- 误用本地存储,Pod 漂移后数据损失
- 错误配置引发集群异常
Kubernetes 对象的易用性,随手可得的各种技巧,都给误操作和危险行为以可乘之机,然而实际情况是,如果是多个团队自行进行运维,可能就会产生五花八门的不同风格的集群,如下图所示:
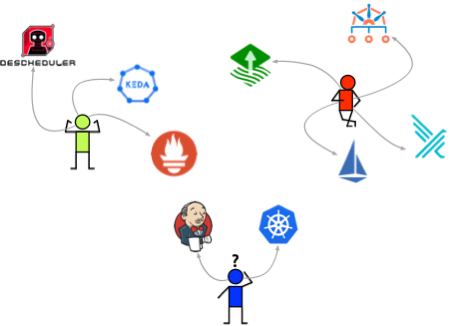
很明显,不同团队因为各自的业务目标、技能水平等,会产生各种不同风格的集群,自然而然,不同的集群,有机会进行不同的“乱搞”,也会出现不同的问题。
我说平台工程
根据流行定义:平台工程是一门设计和构建工具链和工作流的学科,在云原生时代为软件工程组织提供自助服务能力。平台工程师提供一个集成的产品,通常被称为 “内部开发者平台”,涵盖了应用程序整个生命周期的操作需要。
以我所见,平台工程面在三个方面为组织提供支持基础设施、规范和工具:
基础设施
现代软件运行需要大量的基础设施,除了传统的 网络、计算、存储之外,还包括大量的服务化的中间件等能力,OpenStack、Kubernetes 等资源编排工具也属于是传统管控难题。平台团队可以综合基础设施自有的管控运维能力,使用 Terraform、Kubernetes CRD、等资源抽象和自动化手段,为开发团队及其产品,规划、搭建、自动化和优化可靠、安全、高性能的基础设施,以支持业务的运行和发展。
规范
企业 IT 环境通常会有一系列的规范,例如设施命名、账号管理、IP 分配等等;另外操作系统、容器集群等具有极大灵活性的基础设施,也通常是需要有一定的规范化管理的,这里提到的规范至少包括:
- 安全规范:平台团队负责制定和实施安全规范,以确保平台和应用程序的安全性。这可能包括访问控制、身份验证、数据加密、漏洞管理等方面的规范。
- 部署和发布规范:平台团队可以制定规范,定义部署和发布流程,并确保它们得到正确执行。这些规范可以包括环境分离、版本控制、持续集成和持续交付等。
- 最佳实践:各种最佳实践可以通过规范的形式进行推行和实施。将最佳实践转化为规范的形式可以确保团队成员共享相同的理解,并提供具体的指导和标准,以便在组织中广泛应用,例如访问控制规范、文档发布规范、接口管理规范等等。
- 资源规范:例如资源申请和分配、生命周期管理、成本控制、审计和监控等的规范,有助于组织资源的有效利用、成本控制和性能优化。
工具
平台工程的主要产出就是一个被称为 idp(内部开发平台)的工具,以此工具为开发团队提供支持,在实际工作中,工具部分的工作内容至少包括:
- 外部(开源/商业)软件的导入:除了前面提到的采用开源软件的层层关卡之外,平台工程团队还应负责补齐第三方软件的运维能力、外部软件和内部平台的配套对接、开发并实施明确、有效并且成本合理的生命周期管理过程。
- 基础设施的供给、隔离:在基础设施自身服务接口和运维能力基础之上,为各个开发组织以及产品,规划并供给基础设施资源,尽可能让产品团队关注资源本身,并提供成本监测、优化等技术支持能力,用隔离手段防止租户和租户、租户和管理之间的不必要的资源访问。
- Dev(Sec)Ops:包含供应链安全、代码质量、环境管理等的复杂 CI/CD 生命周期相关能力。
- 规范实施:平台或者工具,除了是业务的加速器,同时也是管理意志的执行者。纯文本的规范举步维艰,只有靠策略保障、工具辅助等方式,才能保障规范背后的管理意图的达成。
文章来源于互联网:这叫平台工程吗




