
原文:HOW ZALANDO MANAGES 140+ KUBERNETES CLUSTERS
最近我接到一个问题:“你是如何管理这么多 Kubernetes 的?”。本文试图揭示 Zalando 在 AWS 管理 140 多个 Kubernetes 集群的秘密。
我写过一篇文章:为什么需要多集群,Mikkel 在 KubeCon EU 2018 上做了关于如何在 Kubernetes 基础设施上进行持续交付的精彩分享。这里基本是对现存信息的一个梳理。
背景
Zalando 有 200 多个开发团队,他们全权负责自己的应用,其中也包括 7*24 待命的支持工作。我们的 Kubernetes 平台团队为 1000 多个 Zalando 开发者提供 Kubernetes 即服务的支持工作,工作过程中我们遵循如下准则:
- 杜绝手工操作:所有集群更新和运维都要全自动。
- 没有宠物集群:集群应该整齐划一,无需任何额外的配置和微调。
- 韧性:为交付团队提供稳固的基础设施,保障其关键应用的运行环境。
- 自动伸缩:集群应该自动适应应用负载的规模,根据需求进行伸缩。
架构
我们的集群是成对供应的,例如给每个域或者“产品社区”提供一个生产、一个非生产环境。
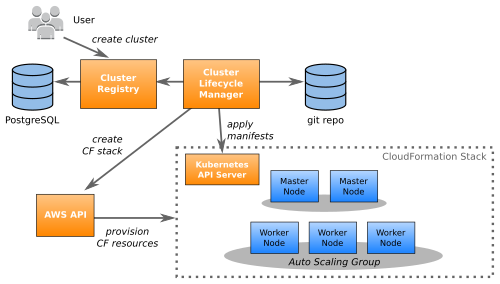
每个集群都是属于一个全新的、隔离的 AWS 账号。我们使用一个自定义的 Python 工具(Seven Seconds)对 AWS 基础设施进行配置,对 Kubernetes 和非 Kubernetes 账号一视同仁(即将下线的 STUPS 基础设施)。
我们整个生产环境的配置都保存在 Github 上。集群使用 CloudFormation(CF)模板。每个集群至少有四个 CF 栈:
- ETCD 集群(存在于主节点之外):etcd-cluster.yaml
- 主集群:cluster.yaml
- 主机群节点池:master stack.yaml
- 缺省的工作节点池:worker stack.yaml
可以有多种工作节点池,例如 GPU 节点、EC2 Spot 实例等。
注意:我们没有使用 Terraform(从来没有)。
主节点和工作节点都运行在我们的自定义 AMI 上。这个 AMI 是从 Ubuntu 基础上构建出来的,并且包含了 Kubernetes 所需的所有 Docker 镜像。从前我们用过 ContainerLinux,后来还是决定采用更主流的发行版,以保证持续性。这个预制的 AMI 还帮我们减少了启动时间(集群伸缩更快)。
配置
所有的集群以及 AWS 账号,都注册在一个中央集群仓库中。集群仓库使用 PostgreSQL 为数据库,提供了一组 REST API。可以在 Github 上浏览这个 OpenAPI 的规范。每个集群都有如下属性:
- 只读的集群 ID,例如 “aws:123123123123:us-east-1:kube-9”
- 集群别名:例如 “foobarlab”
- 所在的 AWS 账号(账号 ID 和 Region)
- 环境(生产还是测试)
- 配置成熟度(稳定、Beta、Alpha 或者 dev)
- 生命周期(已供给、已分配或者已销毁)
- 集群特定的键值对信息,例如外部 API Key 等。
- 已配置好的节点池(也就是 EC2 实例类型)和针对节点池的键值对配置
我们的工具集(kube-resource-report 和 kube-web-view)能够查询集群仓库的 REST API,列出所有集群,比如 zkubectl 命令行工具能够列出集群:
$ zkubectl list
Id │Alias │Environment│Channel│Version
aws:123740508747:eu-central-1:kube-1 foobarlab production stable 5f4316c
aws:456818767898:eu-central-1:kube-1 foobarlab-test test beta 9f1b369
aws:789484029646:eu-central-1:kube-1 abckub production stable 5f4316c
aws:012345670034:eu-central-1:kube-1 abckub-test
...
你会看到两对集群(foobarlab 和 abckub),生产集群使用的是 stable,非生产集群则使用 beta 配置。Version 列显示的是当前集群配置的 git sha。
用 Kubernetes Web View 对类似的集群进行渲染:
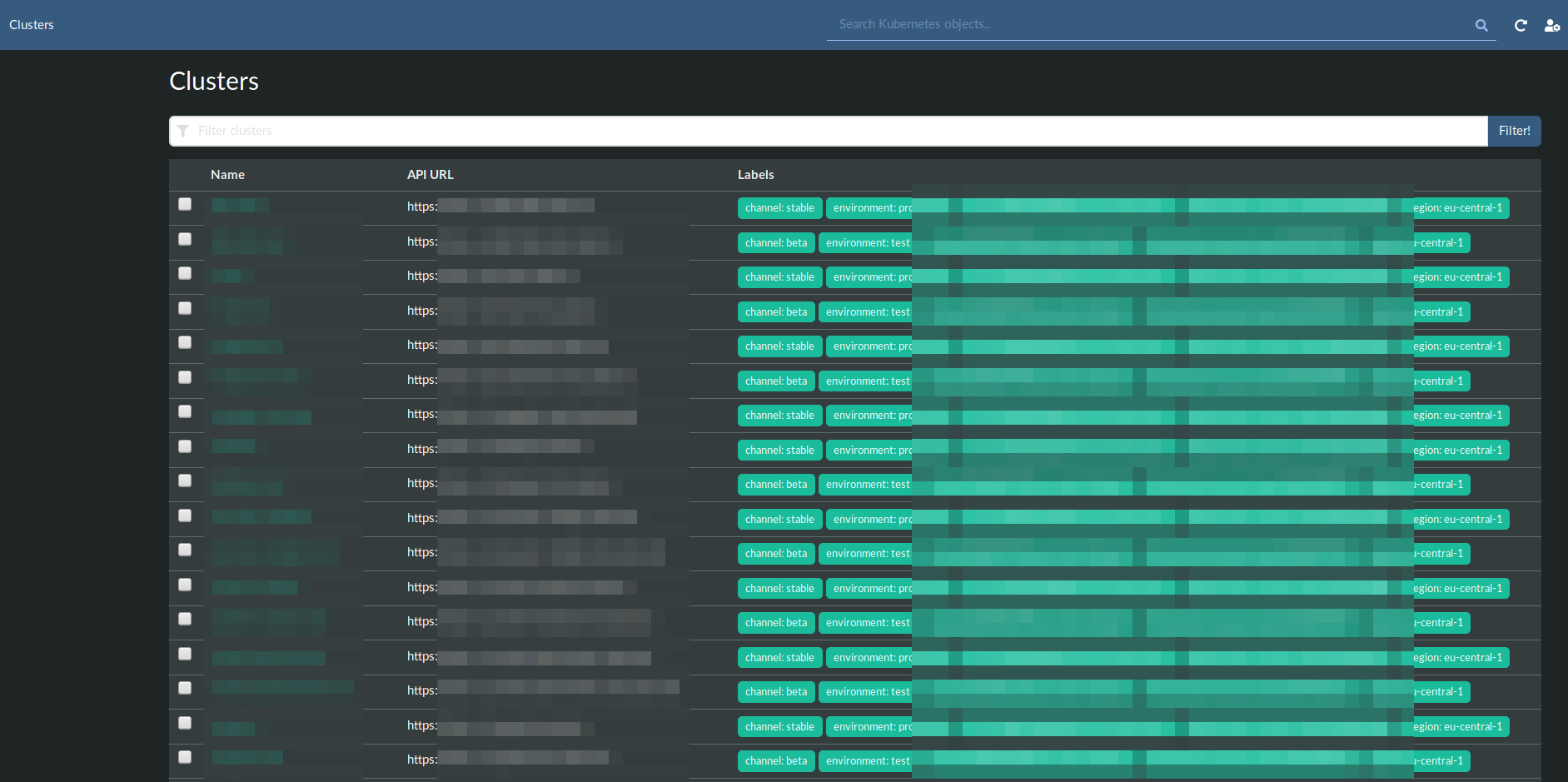
还可以参考我的另一篇文章:缺乏多集群支撑案例的 Kubernetes Web UI。
更新
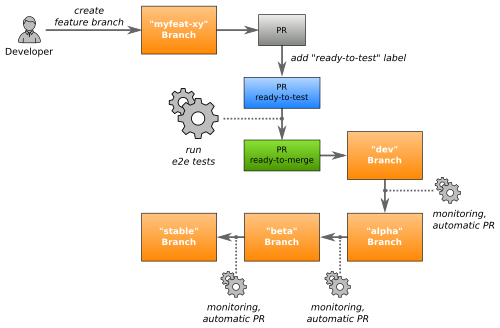
集群生命周期管理器持续的对集群仓库以及 Git 仓库的变更进行监控。CLM 会在如下时机进行变更:
- CloudFormation 更新
- 节点必须进行滚动更新(例如 AMI 发生变化)
- Kubernetes 自身发生了变更(多数时候的表现是
kube-system中的 DaemonSet 和 Deployment 的变更)
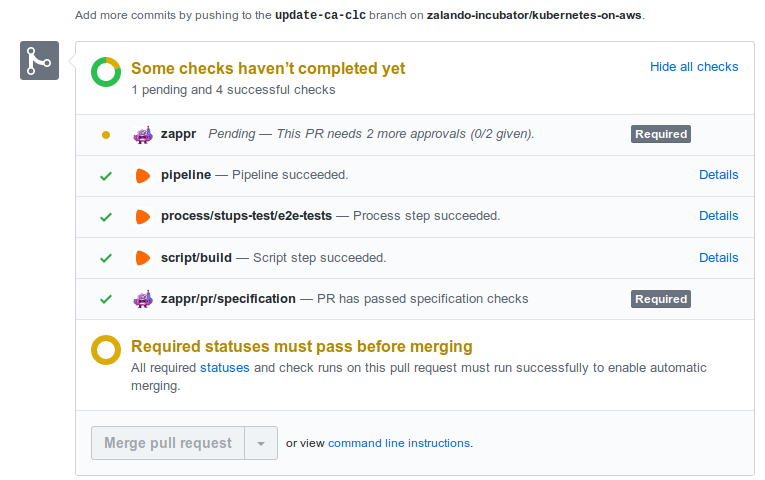
通过对 dev 分支发起 PR 的方式来初始化一个更新动作(例如更新一些系统组件)。每个变更的 PR 都会自动的进行端到端测试。 只有通过测试并且由人手工批准的 PR 才能够合并。端到端测试过程会针对新建的集群运行官方的 Kubernetes 一致性验证,以及 Zalando 自己的测试案例。这个测试的范围包括:
- 集群的创建和更新(端到端测试会用前一个版本创建一个新的集群,并用 PR 内容进行更新)
- Kubernetes 的核心功能:Deployment、StatefulSet 等
- Zalando 的准入控制器逻辑
- 审计日志
- Ingress、外部 DNS、AWS ALB 以及 Skipper
- PodSecurityPolicy
- 使用自定义指标进行自动伸缩
- 测试 AWS IAM 集成
每个 e2e 测试目前需要 35-59 分钟。测试成功的 PR,只需要一个 +1,就能进行合并:
每个变更都会在不同的分支中迁移,一直到进入稳定分支。
在滚动更新集群节点以及集群的自动伸缩过程中,我们的基础设施必须对正在预备下线的服务器上运行的 Pod 进行驱逐。可以使用 Pod Disruption Budgets 的声明,来保障平稳的更新过程。我们为更新或类似行为定义了下面的 SLA:
| SLA | 生产集群 | 测试集群 |
|---|---|---|
| 更新期间强制终结的 Pod 的最小生存期 | 3 天 | 8 小时 |
| 在选定节点之后,需要等待多久才开始强行终结 Pod | 6 小时 | 2 小时 |
| 同一个节点上强行终结 Pod 的时间间隔 | 5 分钟 | 5 分钟 |
| 同一个 PDB 中将被终止的就绪 Pod 的最小生存期 | 1 小时 | 1 小时 |
| 同一个 PDB 中将被终止的未就绪 Pod 的最小生存期 | 6 小时 | 6 小时 |
因此应用 Pod 会在 3 天之后被强行终止——即使定义了 PDB 的情况。这种行为模式让我们在部分应用配置失常的情况下也能持续更新。
注意:我们的用户(开发团队)可以在任何时间阻止集群更新(例如发现了问题)。
避免配置发散
所有的集群看起来都差不多,只有少量配置项目有些不同:
- Secret:例如外部日志服务的凭据
- 节点池以及其中的实例规格
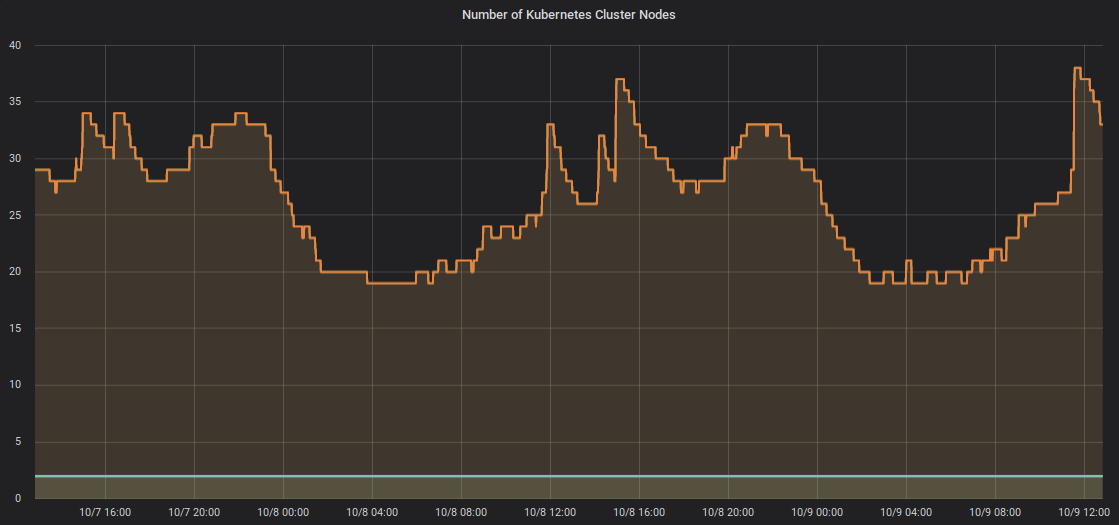
Cluster Autoscaler 能根据资源需要对集群的节点池进行伸缩,无需手工配置节点池的大小。下图是我们一个集群在两天之内的伸缩情况:
有些组件需要根据集群大小进行纵向伸缩。我们使用 Vertical Pod Autoscaler(VPA)来避免对这些值进行手工调节。目前有如下系统组件在使用 VPA:
- Prometheus
- 外部 DNS
- Heapster/Metrics Server
- 我们的 ALB Ingres 控制器
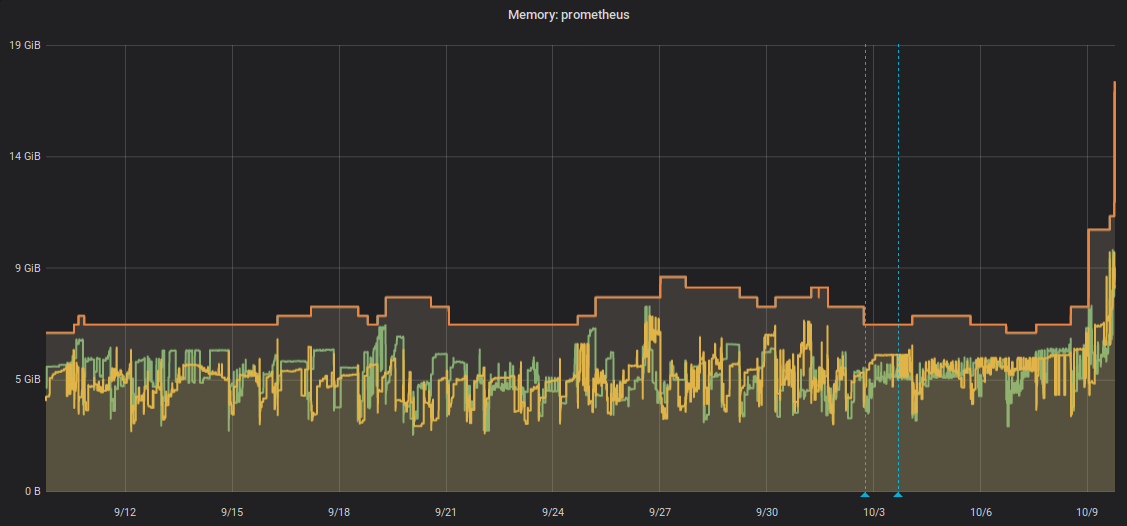
我们最小的 Prometheus 实例仅仅使用 512 MB,也有使用 9GB 的大户,例如下图:
监控
我们主要的监控系统是 ZMON,ZMON 中有个实体的概念,表达的是你要监控的对象——例如服务器、Pod 甚至是团队。
创建一个新的集群会自动注册新的实体(例如新的 AWS 账号、节点、Deployment、Pod 等)。从而为新的实体启用一些常用检查和告警。
ZMON 提供了指标、告警以及仪表盘。
我们的 Kubernetes 团队不会在 Pod 重启时候收到警告。开发团队负责应用的整个生命周期。
我们还使用 OpenTracing(LightStep)获得跨集群的可观察性,中心化应用日志(Scalyr)、kube-resource-report 和 kube-web-view)。
魔改 Kubernetes
我们的配置是否对 Kubernetes 进行了大量魔改呢?答案是:不很多:
- Kubernetes API 认证用了 Zalando Oauth token
- 使用 Kubelet 参数 禁用 CPU Throlling
- 强制 request == limit,防止内存超售
- 使用 外部 DNS ALB Ingress 控制器,以及 Skipper,Ingress 注解是可选的,不过 Skipper 有些有用的功能
-
PlatformCredentialsSet是一个用来集成 OAuth 的 CRD - 我们用 StackSet来实现流量切换和渐进部署
- kube-downscaler 用于在作业后降级测试部署
- 我们的 DNS 配置有些不同:我们使用
ndots: 2的配置(官方配置是ndots: 5)
非生产集群提供的是类似 GKE 或者 Digital Ocean 集群类似的普通集群的功能。生产集群有些容器:
- 只能通过 CICD 进行 Kubernetes API 的操作
- 用 Webhook 执行强制的合规措施,例如使用某些标签,或者允许用于生产的镜像
总结
我们的这种做法再过去几年中工作良好,让我们在无需扩张团队的情况下得到了成长:
- 我们能够无缝的把我们一个老的 Kubernetes 1.4 在无停服的情况下,升级到 1.14
- 我们能够跟进 Kubernetes 的季度发布,也就是说我们在每个季度都可以进行升级
- 频繁的集群更新让大家开始接受一个观点:小的中断是正常的(目前的 Pod 最长寿 20 多天)
- 我们尝试避免出现宠物集群:集群看起来差不多,VPA 协助我们避免人工调节
- 我们的自动端到端测试救了我们不止一次(例如 最近 1.14.7 的 Issue(https://twitter.com/try_except_/status/1181602709155323905))
要进一步了解这方面的信息,可以看看 Zalando 的公开仓库,还可以在 Twitter 上找到我们的一些团队成员:
也欢迎和 ZalandoTech、和我打个招呼。
文章来源于互联网:Zalando 是如何管理 140 多个 Kubernetes 集群的




