
前言
大概很多人和我一样,是从 Istio 那里听说 SPIFFE(读音 Spiffy [ˈspɪfi]) 的,Istio 中用 SPIFFE 方式为微服务提供身份。SPIFFE 全称为 Secure Production Identity Framework For Every one,顾名思义,这是一个解决身份问题的框架;而 SPIRE 则是 SPIFFE 的一个实现,全称为 SPIFFE Runtime Environment。
一个“我是谁”的问题,真的需要大动干戈?甚至能养活两个项目:SPIFFE 和 Spire 这对双子星项目,2018 年以 Sandbox 项目身份加入 CNCF,2020 年进入孵化状态,2022 年毕业——是的不但养活了,甚至还毕业了。
官方出了一本小册子,叫做《Solving The Bottom Turtle —— a SPIFFE Way to Establish Trust in Your Infrastructure via Universal Identity》,内容如副标题所说——用 SPIFFE 的方式在基础设施中,利用统一身份构建信任关系。
这里提到的最下面的乌龟,大意是说,身份问题是一个值得深入挖掘的基石技术,相关的传说可以查看一下机壳的文章:《世界巨龟神话原型:如果世界是一只乌龟
》。
业务和组织之间的关系,往往就代表着人与应用之间、应用与应用之间的交互。大量的微服务架构应用,用水平伸缩、快速迭代的方式在复杂多变的容器、公有云等基础设施上运行,而安全以及合规的要求则日益提高。这种情况下,访问控制的必要性就逐步凸显出来。访问控制的实现,就是乌龟叠叠乐的效果:
- 访问控制要解决的问题就是谁能访问什么的问题
- 这里的“谁”就是认证的问题,对于这个身份,需要进行证明和保护
- 通常的保护方式是把凭据作为敏感数据进行加密
- 那么解密所需的密钥也是敏感数据
- 敏感数据需要安全地进行保存
- 但是,要访问被保护的敏感数据,还是需要有访问控制
- …
要打破死循环,需要一种短生命周期的(易于轮转且不易攻破)、自动化的解决方案。方案中需要有一个可信的根,在这个基础之上来构建软件的身份,而这个身份则成为认证和授权能力的基石。为了防止无穷无尽的下钻过程,工作负载应该能够不借助任何凭据来获得这个身份凭据。
很多厂商在这个方向上做了各种尝试,例如 Google 的 Application Layer Transplort Security(ALTS)、Netflix 的 Marathon 等。
Kubernetes 创始工程师 Joe Beda 在 2016 GlueCon 上发表了题为 Who’s Calling?
Production Identity in a Microservices World 的演讲,其中展示了方案的三个要点:
- 无需凭据,通过内核调用来生成 0 号机密
- 使用大多数软件都支持的 x.509
- 解耦网络位置和认证
专家们在 Netflix 进行了 SPIFFE 草案的研讨。很多成员都已经实现并持续改进工作负载认证的方案,他们发现各自的解决方案都有或多或少的相似性,因此具备形成通用方案的可能性。
解决工作负载身份问题的最初目标是建立一个开放的规范和相应的生产实现。该框架需要在不同的实现和现成的软件之间提供互操作性,其核心是在一个不信任的环境中建立信任的根基,驱除隐性信任。最后,摆脱以网络为中心的身份,以实现灵活性和更好的扩展特性。
SPIFF 的基本概念
SPIFFE 由五个部分组成,分别是 SPIFFE ID、Workload API、SVID、SPIFFE Trust Bundle 以及 SPIFFE Federation。
SPIFFE ID
软件名称或身份的表达方式,一般使用信任域、服务标识组成的一个 URL,例如 Istio 中的 spiffe://
SVID
全称是 Software Verifiable Identify Document,一种加密的可验证的档案,用于证明工作负载的身份。用 CA 签署 SPIFFE 就产生了 SVID,SVID 有两种载体:
-
X509:用 SAN 字段来保存 SPIFFE ID。是推荐的保存方式。
-
JWT:这种方式下,在应用层用 bearer token 的方式来证明身份。考虑到适用范围和安全性问题,不建议使用 JWT 承载 SVID
Workload API
一种简单的本地 API,服务可以无需认证直接调用 API 来获得自己的身份、Trust Bundle 以及相关信息。
Trust Bundle
SPIFFE 的公钥组合
SPIFFE 联邦
一种简单的用于共享 SPIFFE Trust Bundle 的机制
SPIFFE/SPIRE 和其它安全技术的关系
SPIFFE/SPIRE 的能力并不新鲜,毕竟每个分布式系统都有认证的需求,Web PKI、Kerberos/Active Directory、OAuth、敏感信息存储以及服务网格等都和这一领域有着交集。
但现存的这些形式对于组织内部的服务认证并不合适。Web PKI 实现要求比较多,并且在典型的内部部署环境下也不够安全;Kerberos 需要一个一直在线的 Ticket 管理服务,并且缺乏证明能力;服务网格、机密管理器和叠加网络解决的都是服务身份问题中的一部分。SPIFFE 和 SPIRE 是目前唯一完整的服务身份方案。
Web Public Key Infrastructure
Web PKI 广泛应用在从浏览器连接到安全网站的场景里。这种技术用 X.509 证书来向用户证明网站的身份。读者自然会想问——直接用这种技术进行服务认证不就行了吗?
传统的 Web PKI 场景下,证书的签发和更新是手工的,难以适应现代的动态伸缩环境。虽然近年来发展出了自动化的签发和刷新流程(Domain Validation/DV),然而 DV 非常依赖于 IP 和域名规划,而且客户端证书也无法使用 DV 的自动化流程。另外,DV 流程里用于响应 Token 请求的服务是独立的,有可能通过 2 层网络进行仿冒。
AD 和 Kerberos
Kerberos 中的核心凭据被称为 ticket,Ticket 是一个客户端访问一个资源的凭据,客户端通过调用 Ticket Granting Service(TGS)来获取 Ticket。每个客户端在访问资源需要新的 Ticket 的时候都需要访问 TGS,因此需要 TGS 一直在线。所有服务都要信任 TGS。服务注册到 TGS 的时候,需要把密钥物料(例如公钥或者对称密钥)托管到 TGS,TGS 用来为服务创建 Ticket。要对物料进行轮转,需要在服务和 TGS 之间进行协调。服务自己必须接受前任物料签发的过期 Ticket。
而在 SPIRE 里,客户端和资源都要访问 SPIRE 服务器一次,获取 SVID,然后在信任域范围内就可以凭借这些 SVID 进行互信了,无需再次调用 SPIRE Server。SPIRE 的设计避免了大量对 SPIRE Server 进行访问的成本。SPIRE 这样的依赖 PKI 的认证机制,密钥物料已经解耦,所以轮转过程也大为简化。
另外 Kerberos 协议的签署过程和主机名紧密相关,多服务共享主机或集群时,这个情况就会非常复杂;SPIRE 则可以轻松地为工作负载和集群支持多个 SVID。同一个 SVID 也能够授予给多个工作负载。
OAuth 和 OpenID
OAuth 是一种用于委托的访问方式,而不一定需要自己完成认证过程。OIDC 的第一目标就是让自然人使用一个第三方网站作为自己的身份,来访问目标网站。这个第三方网站必须实现自己的认证方法,从而以本地的认证关系为用户向其他网站提供证明。
OAuth 是为人机交互设计的,登录过程中需要进行浏览器的交互;2.0 中加入了对非人实体的支持,通常是用 Service Account 的形式实现。工作负载要拿到 OAuth 凭据来访问远程系统,必须向 OAuth 提供密码或者 Token 等来进行认证。工作负载需要自行维护各自的凭据,从而获得粗粒度的授权能力,这一过程要求每个工作负载都注册到 OAuth 供应侧,因此起管理难度和负载会迅速增加。
OIDC 并没有解决身份的基本问题,实际上是依赖于预制的身份的。相对来说,SPIRE 不需要长寿的初始凭据,以 SPIRE 作为 OIDC 的身份供应者能够有效地提高安全性——应用无需自行准备身份凭据,只需要用 SPIFFE ID 按需认证即可。
敏感信息管理
这类工具通常要负责对敏感信息进行控制、审计和保管,起操作方包括了管理员和一些应用。有些工具还会提供加解密等功能。其加密存储功能通常被称为 vault。应用必须进行认证之后才能访问 Vault 中的数据。这种系统面临的最大挑战通常就是自身的访问控制,通常称为零号凭据。使用 SPIFFE 作为认证机制能更好的解决这一问题。
服务网格
所有的主流服务网格产品都提供了服务认证功能。SPIFFE 的身份提供能力正适用于这种场景,Istio 和 Consule 都可以使用 SPIFFE 提供身份解决方案。
Istio 使用 SPIFFE 用于识别节点,但是他的身份模型耦合在 Kubernetes 上,IBM 认为 Istio 的机制是不足的,因此提供了 SPIRE 和 Istio 的集成方案
叠加网络
叠加网络跨越多个平台模拟了一个统一网络。与服务网格不同的是,叠加网络使用 IP 地址和路由表这样的标准网络概念,来连接服务。最新的覆盖网络开始提供认证能力。在服务连接之前仍然无法验明正身。通常情况下,这种机制都依赖于一个预存证书。因此 SPIFFE 也很适合为叠加网络节点提供证书。
SPIRE 简介
综合前面对 SPIFFE 的讲述,可以知道,这东西的核心能力:
- 工作负载(业务应用)可以通过一种本地的、无需认证的方式获取到一个 SPIFFE ID
- SPIFFE ID 可以签署成为 SVID,SVID 用 X.509 或者 JWT 的形式进行表达
- 不同的工作负载之间,共享 Trust Bundle
- 利用 Trust Bundle 可以鉴别 SVID 的真伪,从而识别出 SPIFFE ID
利用可信的 SVID 所代表的 SPIFFE ID,就可以进行后续的访问控制了。
SPIRE 是如何解决上述问题的?看看官方网站的架构图:
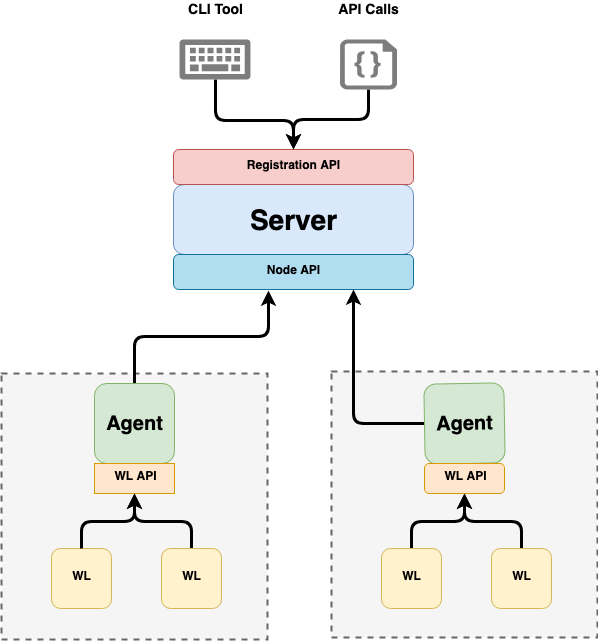
SPIRE 由服务器和 Agent 两部分组成:
- 服务器负责签发 SVID 并通过 Agent 传递给工作负载;另外他还要维护一个工作负载身份的注册表
- Agent 部署在每个节点上,向工作负载公开 Workload API。
这说起来还是非常抽象,为了实现 SPIFFE 规范,SPIRE 引入了一系列自己的概念。
Attestation
SPIRE 中的 Attestation(证实)过程,就是求证工作负载身份的过程。SPIRE 的证实工作氛围两个步骤:
- 先验证节点:保障工作负载所在的节点的身份的有效性
- 再验证工作负载:保证节点上的工作负载是有效的
Node Attestation
节点的证实过程是在 Agent 启动过程中完成的,SPIRE 要求 Agent 在第一次连接到服务器的时候能够验明正身。在节点证实过程中,Agent 和服务器协作对 Agent 所在的节点进行校验。这个过程是通过 SPIRE 中被称为 Node Attestor 的插件完成的,这种插件的基本做法就是对节点以及所在环境进行查询和比对,来验证节点身份的有效性。
节点证实成功之后,Agent 就收到了一个 SPIFFE ID,Agent 会把这个 ID 作为父 ID,发放给运行在这个节点上的工作负载。
几种常见的节点身份的证据:
- 云平台分发给节点的身份文档(例如 AWS 的 Instance Identity Document)
- 节点上 HSM 或者 TPM 硬件的私钥
- 安装 Agent 时候的手工验证过程
- 多节点系统中提供的身份凭据,例如 Kubernetes 的 SA Token
节点证实过程会返回一组属性(Selector)给服务器,这些属性能够标识出特定的节点,另外还会有 Node Resolver 来获取节点的其他属性,这些属性一起,构成了 SPIFFE ID 的附加属性。
例如 AWS 节点的证实过程:
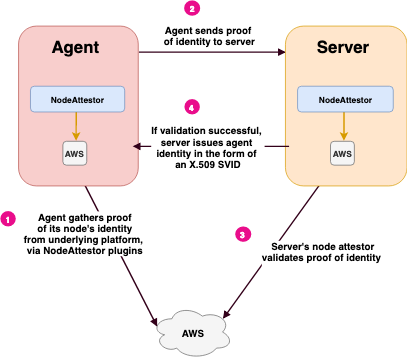
- Agent 上的 AWS Node Attestor 向 AWS 查询节点的身份,发送给 Agent
- Agent 把身份的证据发送给服务器,服务器把信息发送给 AWS Node Attestor(的服务侧)
- AWS Node Attestor 的服务端独立或者调用 AWS API 对前一个步骤获取到的信息进行验证。Node Attestor 还会为 Agent 创建一个 SPIFFE ID,并把 SPIFFE ID 和 Selecor 传给服务器进程
- Server 返回一个 Agent 节点的 SVID
SPIRE 支持多种环境的 Node Attestor,例如:
- AWS 的 EC2 实例(EC2 Instance Identity Document)
- Azure 虚拟机(Azure Managed Service Identities)
- GCE Instance(GCE Instance Identity Token)
- Kuhbernetes 节点(Kubernetes Service Account Token)
对于无法直接认证节点的平台,SPIRE 提供了如下措施:
- 服务器和 Agent 之间可以生成一个预共享密钥作为加入的 Token,Agent 启动时进行验证,使用后立即过期
- 使用现存 X.509 证书
Workload Attestation
工作负载的证实过程要回答的问题是:这个进程是谁?Agent 和 Server 都参与到了节点证实过程里;而工作负载的证实过程是由 Agent 完成的。
下图展示了工作负载证明的过程:

- 工作负载调用 Workload API 申请 SVID。在 Unix 系统中,这个 API 表现为一个 Unix Domain Socket
- Agent 调用节点的内核来认证调用者的进程 ID。然后回调用工作负载的证实插件,把进程号提供给他们
- 利用进程 ID 查询工作负载的额外信息,可能会和 Kubelet 等同节点服务进行交互
- Attestor 把进程信息返回给 Agent
- Agent 把属性和注册信息进行比对,返回合适的 SVID 给工作负载。
工作负载的证实机制目前支持 Unix、Kubernetes 和 Docker。
SVID 的生命周期
这一节内容讲述了 SPIRE 签发工作负载身份的过程。这个过程从 Agent 在节点上启动开始,持续到工作负载收到有效的 X.509 SVID 为止(注意,JWT 和 X.509 的处理方式是不同的)。下面以 AWS EC2 为例。
- SPIRE Server 启动
- 除非用户配置了上游 CA 插件,Server 会生成一个自签名证书;Server 会使用这个证书来给信任域内所有的工作负载签发 SVID
- 如果这是首次启动,Server 会自动生成 Trust Bundle,这些内容会被存储在 SQL 数据库中
- Server 开启注册 API,允许注册工作负载
- SPIRE Agent 在运行了工作负载的节点上启动
- Agent 执行节点证实工作,向 Server 证明节点的身份。例如在 AWS EC2 实例上,通常会把 AWS Instance Identity Document 提交给服务器
- Agent 把身份的证据用 TLS 提交给 Server。TLS 的认证通过 Agent 的 Bootstrap Bundle 来完成
- Server 调用 AWS API 对这些证据进行校验
- AWS 确认文档的有效性
- Server 对节点进行解析,验证 Agent 节点的附加属性,并更新注册数据。例如节点使用的是 Azure Managed Service Identity(MSI)。Resolver 会根据 SPIFFE ID 解析 Tenat ID 以及 Principal ID,并用多种 Azure Service 获取额外信息
- Server 给 Agent 签发一个 SVID,证实 Agent 的身份
- Agent 用它的 SVID 以及他的 TLS 客户端证书联系 Server,获得它被授权的注册内容
- Server 用 Agent 的 SVID 验证 Agent 的身份。Agent 接下来会完成 mTLS 握手,使用 Bootstarap Bundle 完成认证。
- Server 从数据库中抓取所有(该 Agent 下的)认证的注册条目,发送给 Agent
- Agent 发送工作负载的 CSR 给 Server,Server 会签署和返回 Workload SVID 给客户端,客户端进行缓存
- 启动过程完成,Agent 开始监听 Workload API 的 Socket
- Workload 调用调用 Workload API,申请 SVID
- Agent 通过调用 Workload Attestor 来初始化 Workload 的证实过程,证实过程的输入以工作负载的进程 ID 启动
- Attestor 使用内核和用户空间的调用,发现工作负载的附加信息
- Attestor 把发现的信息返回给 Agent
- Agent 通过比对缓存中的注册信息和 Workload 上报的信息,来决定是否把缓存中的 SVID 返回给工作负载。
SPIRE Quick Start
是的完全来自官网
Release 页面没有提供 ARM 架构的发布包,差评,只好自己构建:
$ git clone --single-branch --branch v1.4.0 https://github.com/spiffe/spire.git
$ cd spire
$ go build ./cmd/spire-server
$ go build ./cmd/spire-agent
...
然后用源码包里面的默认配置启动服务器:
$ bin/spire-server run -config conf/server/server.conf &
...
INFO[0000] Starting TCP server address="127.0.0.1:8081" subsystem_name=endpoints
INFO[0000] Starting UDS server address=/tmp/spire-registration.sock subsystem_name=endpoints
做一下健康检查:
$ bin/spire-server healthcheck
Server is healthy.
前面提过用 Bootstrap Token 证实节点身份的方法,这里生成一个 Token:
$ bin/spire-server token generate -spiffeID spiffe://example.org/myagent
Token: ff19d99e-e3f2-446f-86eb-cb37fcbd6574
下面启动一个 Agent,并进行健康检查:
$ bin/spire-agent run -config conf/agent/agent.conf -joinToken
$ bin/spire-agent healthcheck
Agent is healthy.
为了让 SPIRE 能识别工作负载,必须把工作负载用注册项的方式注册到 SPIRE 服务器上。注册过程告知 SPIRE 认证工作负载的方法,以及工作负载的 SPIFFE ID。
下面的命令用当前用户的 UID 创建了一个注册项:
$ bin/spire-server entry create
-parentID spiffe://example.org/myagent
-spiffeID spiffe://example.org/myservice
-selector unix:uid:$(id -u)
Entry ID : 2c0325c5-e5b4-433a-a675-059cbf19f8aa
SPIFFE ID : spiffe://example.org/myservice
Parent ID : spiffe://example.org/myagent
Revision : 0
TTL : default
Selector : unix:uid:501
此时可以在服务侧列出当前的注册条目:
$ bin/spire-server entry show
Found 2 entries
Entry ID : 521fd101-031a-42bf-8190-696bd315e2d3
SPIFFE ID : spiffe://example.org/myagent
Parent ID : spiffe://example.org/spire/agent/join_token/ff19d99e-e3f2-446f-86eb-cb37fcbd6574
Revision : 0
TTL : default
Selector : spiffe_id:spiffe://example.org/spire/agent/join_token/ff19d99e-e3f2-446f-86eb-cb37fcbd6574
Entry ID : 2c0325c5-e5b4-433a-a675-059cbf19f8aa
SPIFFE ID : spiffe://example.org/myservice
Parent ID : spiffe://example.org/myagent
Revision : 0
TTL : default
Selector : unix:uid:501
这个注册条目的 Selector 字段表示用 uid 501 这个条件可以给出 spiffe://example.org/myservice 这个 SPIFFE ID。
这里使用的是 unix Workload Attestor,SPIRE 通过插件的方式支持多种 Node Attestor 和 Workload Attestor,例如 SSH、Kubernetes、AWS、Docker 等等。上面的例子中使用了 unix Attestor 除了这个 uid 之外,还能够支持执行路径、二进制哈希等的 Selector
接下来模仿进程,从 Agent 获取一个 x509-SVID。x509-SVID 可以用于不同工作负载之间的访问控制,下面的命令把 SVID 写入 /tmp:
$ bin/spire-agent api fetch x509 -write /tmp/
Received 1 svid after 253.934417ms
SPIFFE ID: spiffe://example.org/myservice
SVID Valid After: 2022-10-05 14:45:30 +0000 UTC
SVID Valid Until: 2022-10-05 15:45:40 +0000 UTC
Intermediate #1 Valid After: 2022-10-05 09:01:24 +0000 UTC
Intermediate #1 Valid Until: 2022-10-06 09:01:34 +0000 UTC
CA #1 Valid After: 2018-05-13 19:33:47 +0000 UTC
CA #1 Valid Until: 2023-05-12 19:33:47 +0000 UTC
Writing SVID #0 to file /tmp/svid.0.pem.
Writing key #0 to file /tmp/svid.0.key.
Writing bundle #0 to file /tmp/bundle.0.pem.
看到生成了几个 .pem、.key 文件,查看几个文件的内容,会发现:
-
bundle.0.pem中是一个自签发的根证书:... X509v3 Basic Constraints: critical CA:TRUE X509v3 Key Usage: critical Certificate Sign, CRL Sign X509v3 Subject Alternative Name: URI:spiffe://local ... -
svid.0.pem中包含了两个证书,其中一个是中间 CA,另一个是可用于服务侧和客户侧的身份证书
检查签发关系会发现是 bundle.0.pem 签发了 svid.0.pem 中的中间证书,中间证书签发了身份证书。
根据上面的过程大致可以推断出,Server 启动成功之后,Agent 首先自己通过某种方式获得了自己的“合法身份”(例如例子中使用的 Token)。Server 侧预制了若干策略(例如前面注册的 uid=501),Agent 拿到这些策略之后,根据其“本地”的工作负载情况,符合 Selector 要求的内容,就直接发放 SVID。
小结
零敲碎打的阅读了官网文档以及这篇 PDF 之后,对其中种种的严密思考深感折服,同时也感觉,对于缺乏零信任基础设施的组织来说,SPIFFE/SPIRE 是个不可多得的致敬目标,其中对于 Server、Agent、插件的职责划分和流程保障都非常值得借鉴(抄袭)。
然而仅凭这一个技术和产品要达成安全目标也是不现实的,就拿前面提到的 Node Attestor、Workload Attestor,很明显需要根据企业 IT 实际环境,进行插件的选择甚至开发;各种 Selector 的选用和具体实施过程,策略如何保障权威性和最小权限原则,CI/CD、不可变基础设施、配置漂移等问题,都有可能对 SPIFFE 证实过程的干扰甚至破坏;策略的制定过程似乎也是个充满挑战的过程。还好文档中对于联邦的设计、高可用部署、各种典型的集成方式都有相当细致的介绍,非常值得深入学习。
文章来源于互联网:SPIFFE/SPIRE 从入门到入门




